SQL优化问题 #
慢SQL #
MySQL 中有⼀个叫 long_query_time 的参数,原则上执⾏时间超过该参数值的 SQL 就是慢 SQL,会被记录到慢查询⽇志中。
MariaDB [db01]> show variables like 'long_query_time';
+-----------------+-----------+
| Variable_name | Value |
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
1 row in set (0.002 sec)
也就是大于10s,就会被记录成慢SQL.
基本执行过程 #
Server层负责一些验证,权限/身份查询,是否命中缓存,是否使用innodb进行真正的查询,以及写入缓存的问题.分析器分析SQL语法是否出错.
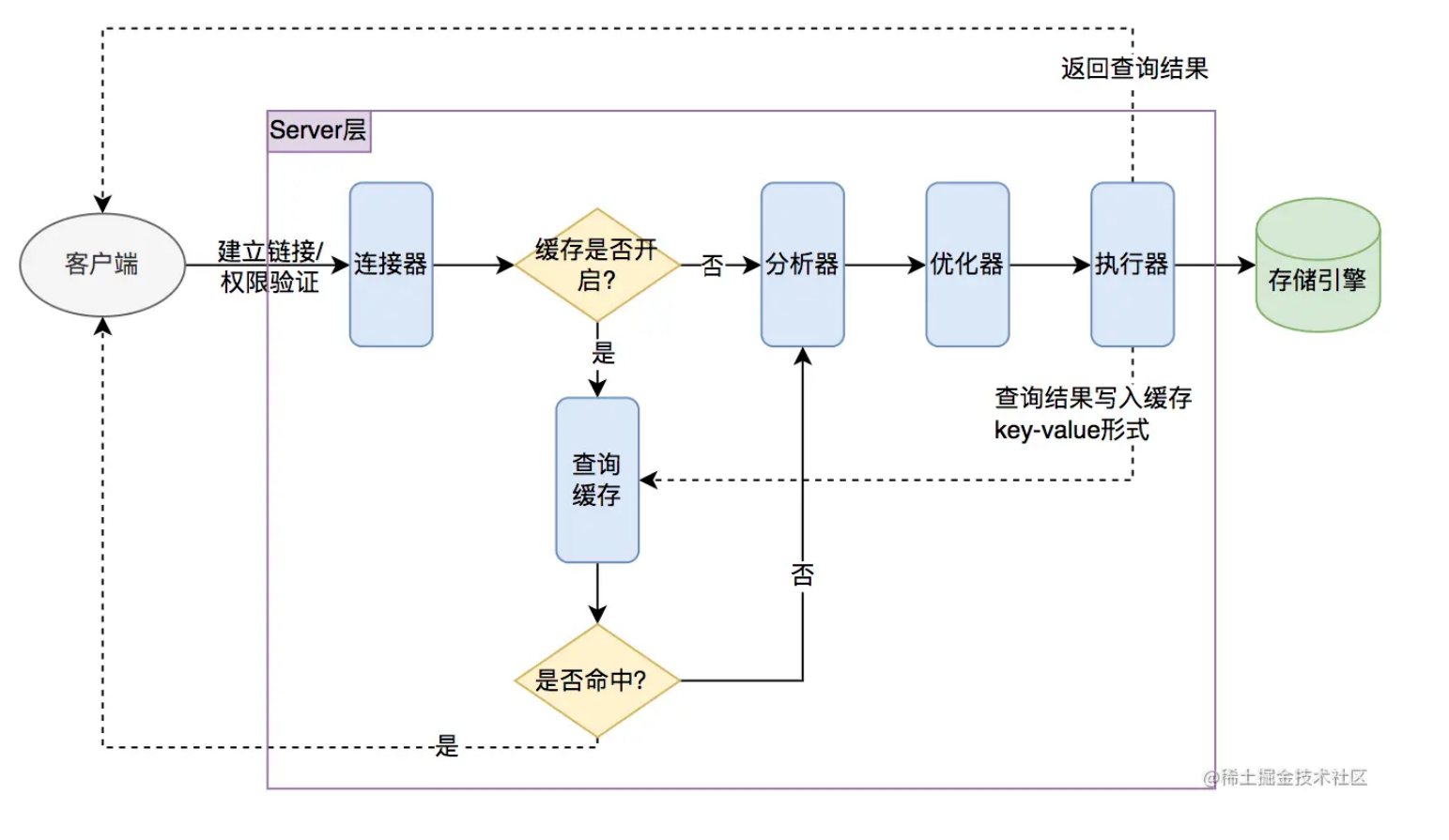
- 客户端发送 SQL 语句给 MySQL 服务器。
- 如果查询缓存打开则会优先查询缓存,缓存中有对应的结果就直接返回。不过,MySQL 8.0 已经移除了查询缓存。这部分的功能正在被 Redis 等缓存中间件取代。
- 分析器对 SQL 语句进⾏语法分析,判断是否有语法错误。
- 搞清楚 SQL 语句要⼲嘛后,MySQL 会通过优化器⽣成执⾏计划。
- 执⾏器调⽤存储引擎的接⼝,执⾏ SQL 语句。 SQL 执⾏过程中,优化器通过成本计算预估出执⾏效率最⾼的⽅式,基本的预估维度为: IO 成本:从磁盘读取数据到内存的开销。 CPU 成本:CPU 处理内存中数据的开销。 基于这两个维度,可以得出影响 SQL 执⾏效率的因素有: ①、IO 成本,数据量越⼤,IO 成本越⾼。所以要尽量查询必要的字段;尽量分⻚查询;尽量通过索引加快查询。 ②、CPU 成本,尽量避免复杂的查询条件,如有必要,考虑对⼦查询结果进⾏过滤。
怎么优化一些慢SQL? #
EXPLAIN SELECT * FROM your_table WHERE conditions;
查看一些慢SQL的执行计划,一般都是因为没有使用到索引导致的.
SQL 优化的⽅法⾮常多,但本质上就⼀句话:尽可能少地扫描、尽快地返回结果。 最常⻅的做法就是加索引、改写 SQL 让它⽤上索引,⽐如说使⽤覆盖索引、让联合索引遵守最左前缀原则等。
比如怎么利用覆盖索引? #
如果我们只给一个非主键建立索引,那么会先在这个非聚集的索引中找到,接着还要再在主键建立的索引中查找,这就叫 回表查询.
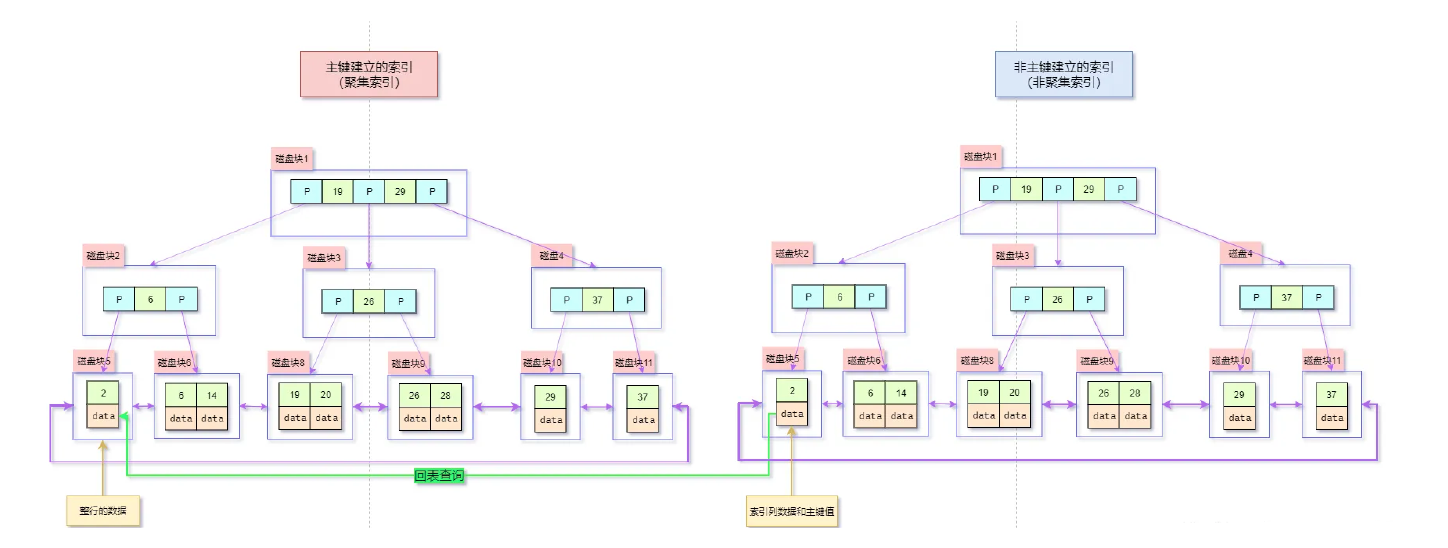
select name from test where city='上海'
比如这条语句,那么name字段就需要回表查询.
那么我们就建立一个组合的索引,把name 覆盖 起来,这是比较好的.
alter table test add index index1(city,name)
这样第一次查询就可以直接返回结果.
最左前缀原则 #
我们怎么保证在一个联合索引的查询中,一定能使用到索引.
CREATE INDEX idx_name_age_sex ON user(name, age, sex)
比如有三个字段,很简单,无论什么查找,一定要保证name在条件的最前方.
分页优化问题 #
添加书签的⽅式是通过记住上⼀次查询返回的最后⼀⾏主键值,然后在下⼀次查询的时候从这个值开始,从⽽跳过偏移量计算,仅扫描⽬标数据,适合翻⻚、资讯流等场景。
变慢就是因为,我们利用OFFSET查询,必须把整张表都进行一遍扫描,哪怕只是为了返回一条数据.
Join连接使用小表驱动大表优化 #
-
当使⽤ left join 时,左表是驱动表,右表是被驱动表。
-
当使⽤ right join 时,刚好相反。
-
当使⽤ join 时,MySQL 会选择数据量⽐较⼩的表作为驱动表,⼤表作为被驱动表。
-
这里的数据量较小是指实际参与join的数据量的大小,而不是表的总行数的问题.
-- ⼩表驱动(⾼效)
SELECT * FROM small_table s
JOIN large_table l ON s.id = l.id; -- l.id有索引
-- ⼤表驱动(低效)
SELECT * FROM large_table l
JOIN small_table s ON l.id = s.id; -- s.id⽆索引
避免Join关联过多的table #
1.我们优化路径的成本过高:

SELECT * FROM A
JOIN B ON A.id = B.a_id
JOIN C ON B.id = C.b_id
JOIN D ON C.id = D.c_id
JOIN E ON D.id = E.d_id; -- 5 个表,优化器需评估 5! = 120 种顺序
2.中间的结果集合可能缓存过多,导致必须要把内存中的临时表存放到磁盘当中去,这样性能就会很差了.
排序优化 #
1.对于order by的字段创建index:
-- 优化前(可能触发 filesort)
SELECT * FROM users ORDER BY age DESC;
-- 优化后(添加索引)
ALTER TABLE users ADD INDEX idx_age (age);
2.遵循最左前缀的原则,即使是在order by的时候,也需要把联合索引最左边的字段放到前面:
-- 联合索引需与 ORDER BY 顺序⼀致(age 在前,name 在后)
ALTER TABLE users ADD INDEX idx_age_name (age, name);
-- 有效利⽤索引的查询
SELECT * FROM users ORDER BY age, name;
-- ⽆效案例(索引失效,因 name 在索引中排在 age 之后)
SELECT * FROM users ORDER BY name, age;
调整一些参数:
1.sort_buffer_size:⽤于控制排序缓冲区的⼤⼩,默认为 256KB。也就是说,如果排序的数据量⼩于 256KB,MySQL 会在内存中直接排序;否则就要在磁盘上进⾏ filesort。 2.max_length_for_sort_data:单⾏数据的最⼤⻓度,会影响排序算法选择。如果单⾏数据超过该值,MySQL会使⽤双路排序,否则使⽤单路排序。 3.max_sort_length:限制字符串排序时⽐较的前缀⻓度。当 MySQL 不得不对 text、blob 字段进⾏排序时,会截取前 max_sort_length 个字符进⾏⽐较。
What is filesort? #
当不能使⽤索引⽣成排序结果的时候,MySQL 需要⾃⼰进⾏排序,如果数据量⽐较⼩,会在内存中进⾏;如果数据量⽐较⼤就需要写临时⽂件到磁盘再排序,我们将这个过程称为⽂件排序。
也就是没有index,查询必然会触发filesort,很尴尬.
全字段排序和 rowid 排序 #
这其实就是没有index索引的时候,使用filesort的两种方法.
1.全字段排序会一次取出所有的字段在buffer内部进行排序.
2.不会把所有的字段都取出在buffer中进行排序,我们中间要回一次表.
MySQL 在执⾏排序操作时,会经历两个过程: 1.内存排序阶段,MySQL ⾸先尝试在 sort buffer 中进⾏排序。如果数据量⼩于 sort_buffer_size 缓冲区⼤⼩,会完全在内存中完成快速排序。 2.外部排序阶段,如果数据量超过 sort_buffer_size,MySQL 会将数据分成多个块,每块单独排序后写⼊临时⽂件,然后对这些已排序的块进⾏归并排序。每次归并操作都会增加 Sort_merge_passes 的计数。
基本过程:
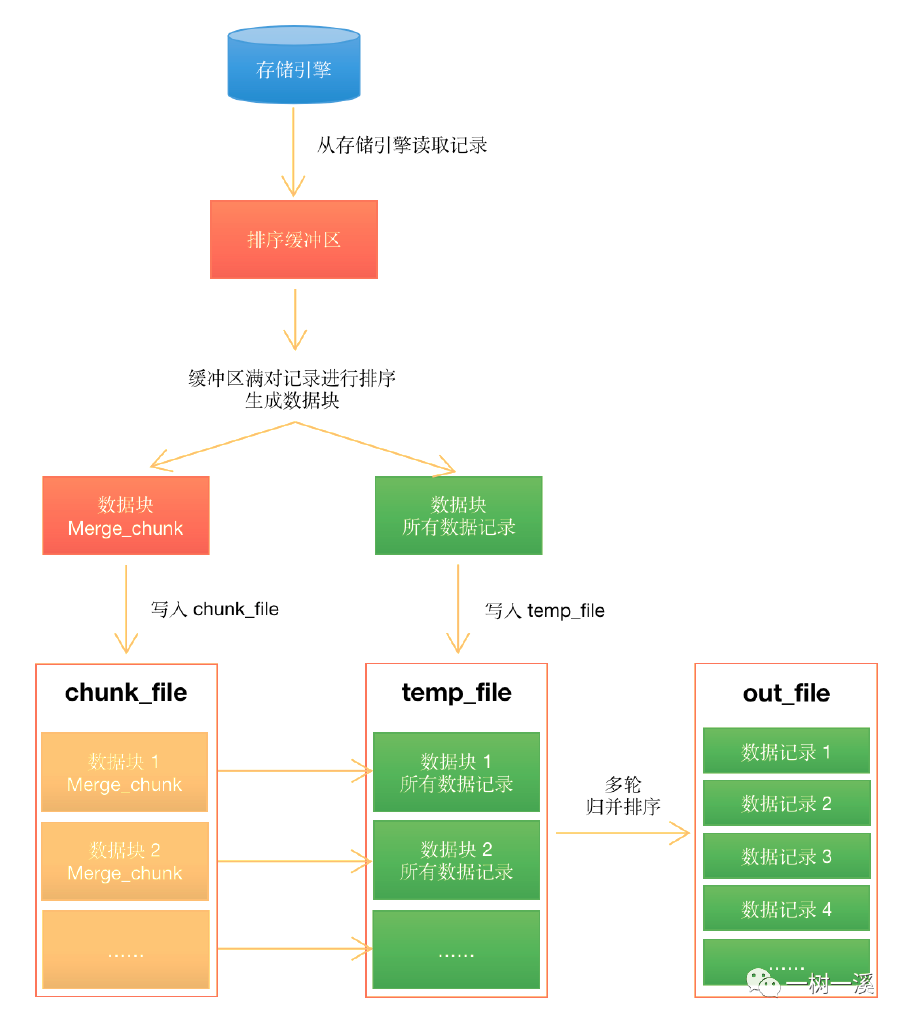
我没看懂这张图,buffer满了就要写入磁盘进行归并排序的意思么?
条件下推 #
这个核心思想就是扫描更少的数据,或者子查询可以返回更少的数据.
比如:
SELECT * FROM (
SELECT * FROM orders WHERE total > 100
) AS subquery
WHERE subquery.status = 'shipped';
那么既然你的子查询查询的都是一张table,我们就把条件 下推 到子查询:
SELECT * FROM (
SELECT * FROM orders WHERE total > 100 AND status = 'shipped'
) AS subquery;
比如:
(SELECT * FROM t1)
UNION ALL
(SELECT * FROM t2)
ORDER BY col LIMIT 10;
既然都只有10个,就没有必要查全部数据:
(SELECT * FROM t1 ORDER BY col LIMIT 10)
UNION ALL
(SELECT * FROM t2 ORDER BY col LIMIT 10);
这个比较常见,比如join原始查询:
SELECT * FROM orders
JOIN customers ON orders.customer_id = customers.id
WHERE customers.country = 'china';
优化:
SELECT * FROM orders
JOIN (
SELECT * FROM customers WHERE country = 'china'
) AS filtered_customers # 这里join的表就会是一个比较小的过滤之后的table.
ON orders.customer_id = filtered_customers.id;
注意:
1.不要使用 != <> 操作符,index失效.
2.不要在列上使用函数,因为要先进行计算,所以也不能使用index.
Explain查询计划 #
我们使用explain来分析一个sql的性能问题.
explain select * from students where name='nunotaba';
就是查看是否进行了filesort,是否使用了索引.
在 EXPLAIN 输出结果中我最关注的字段是 type、key、rows 和 Extra。 我会通过它们判断 SQL 有没有⾛索引、是否全表扫描、预估扫描⾏数是否太⼤,以及是否触发了 filesort 或临时表。⼀旦发现问题,⽐如 type=ALL 或者 Extra=Using filesort,我会考虑建索引、改写 SQL 或控制查询结果集来做优化。
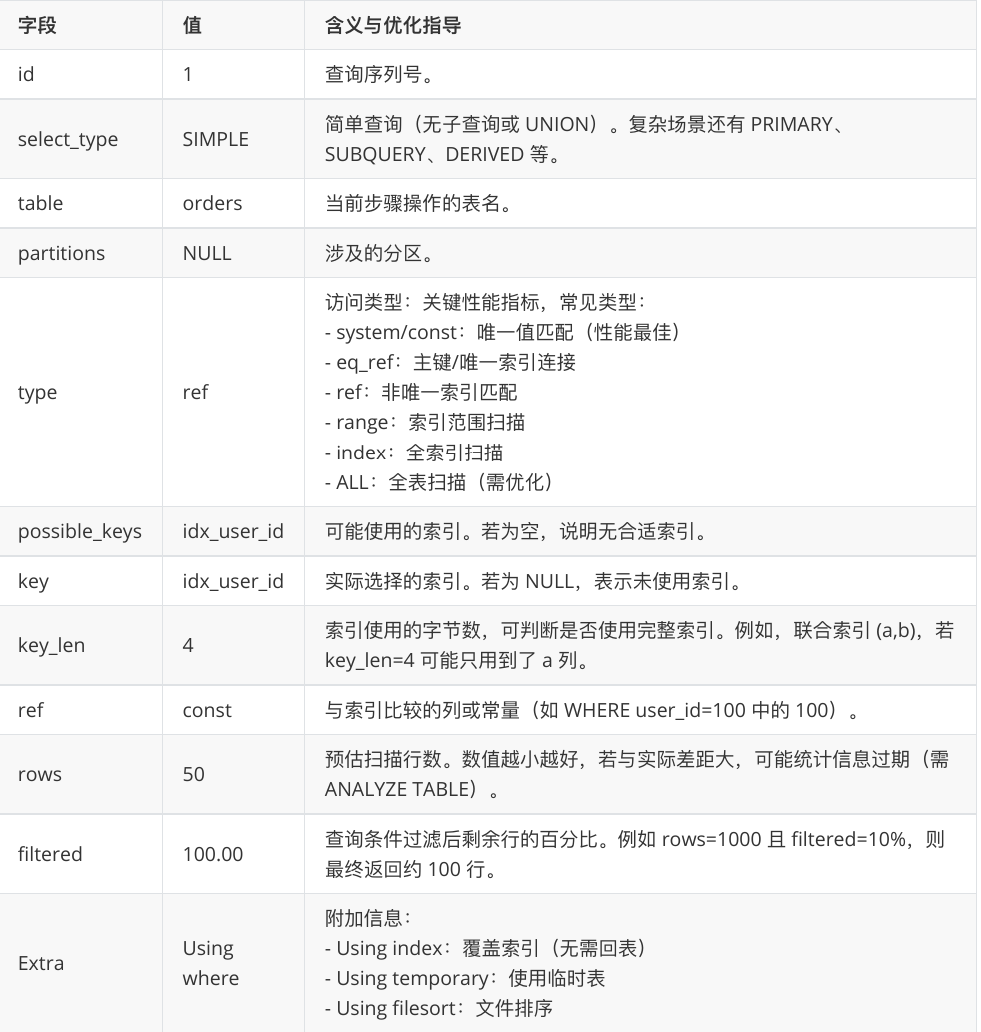
这就是我们关注的一些参数.
type查询需要到什么等级比较合适? #
从⾼到低的效率排序是 system、const、eq_ref、ref、range、index 和 ALL。 ⼀般情况下,建议 type 值达到 const、eq_ref 或 ref,因为这些类型表明查询使⽤了索引,效率较⾼。 如果是范围查询,range 类型也是可以接受的。 ALL 类型表示全表扫描,性能最差,往往不可接受,需要优化。