本期封面是笔者早期最喜欢的动漫角色之一,《とある科学の超電磁砲》中的长点上机学园的天才少女布束砥信,至今笔者的github头像都是她……
MySQL基础 #
1.2024.7.6,本文仅仅是笔者对于SQL语句的简单熟悉和复习的笔记,所以并不会对于更深刻的细节进行考究,也不会介绍怎么安装和配置MySQL的环境以及为什么我们要使用关系型数据库。Linux肯定是最方便的.
2.2025.10.8,为了找实习,我们进行第二次的学习,会深入一些关于SQL的细节问题.
3.练习,练习,练习,开始时不要过度依赖图形化工具.这会让你失去手写的能力!
4.2025.11.14,深入数据库原理,针对面试学习.
数据库的连接:
mariadb -q root -p
企业—>远程连接.
关系型数据库—>二维表关联.
DBMS—>内置的数据库管理系统.—>一个数据库下存放多张table.
语言分类 #
DDL Define—>数据库定义语言,数据库,表,字段的创建等.
DML Manipulation—>数据库操作语言,数据CRUD.
DQL Query—>查询,查询数据记录.
DCL Control—>控制访问权限问题,其实就是数据库的用户权限的问题.
查看当前正在操作的数据库:
MariaDB [db01]> select database();
这里的database都可以替换成schema.
可以使用一些图形化操作工具.
1.Table #
创建表:有B格地创建一张表—>创建的时候使用约束.
字段约束:
not null—>非空
unique—>数据要唯一
primary key—>主键(auto_increment 自动增长)
default—>未指定的情况下有一个默认值
foreign key—>外键约束,两张表建立连接

查看表结构:
desc <table_name>;
delete:drop table if exists;
查看所有表:
show tables;
更高级的,查看当时创建表时候的语句:
show create table <table_name>;
修改表字段
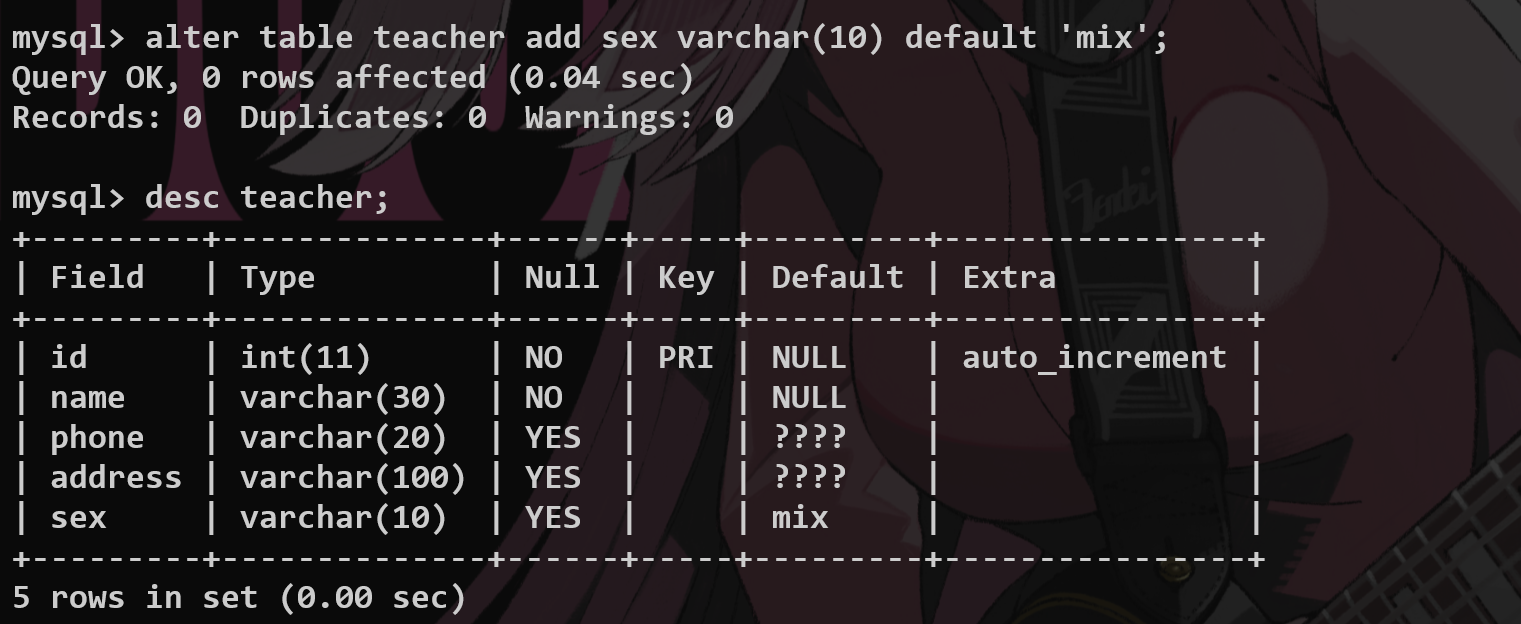
alter table <name> add(增加字段)/change(修改名称)/modify(修改类型) <name> <name1>……
alter table <name1> rename to <name2>
delete from student;
绝对不要用这样的方式去清空一张表
1.遍历删除,会浪费时间和资源
2.若设置auto increment 主键,那么再加入数据的时候会从原来增长的部分继续
truncate table student;
直接报废表并且创建一张和原来一样的新表
2.Data #
DML—>对于数据进行操作.
直接根据字段进行插入:
insert into teacher values (2, 'Touma', 'Male');
你也可以进行批量的操作:—>这是直接针对字段进行插入的操作.
insert into teacher (name, sex) values ('Haruki', 'Male'), ('Oi', 'Female');
1.插入的值和字段一一对应.
2.字符串和日期包含在引号内部.
3.插入数据满足约束的要求.
update data:
没有where就会更新整张表的所有行.
update <tablename> set <field> = <newValue> where <field> = <value>;
search data from table:
select <fieldname,…> from <tablename>;
select* from<tablename>
delete:
delete from teacher where id = 3;
还是不要delete from 做所谓的遍历删除.
3.DataType #
数值类型/字符串类型/时间日期类型
针对字段选取合适的数据类型,直接查询就可以.
日期 date/date_time—>每次创建或者更新都要有create_time,update_time,id作为基础字段,其余自己增加的都是原型字段.
Decimal数据存储原理?—>以字符串的形式来进行存储.
decimal(5,2)—>5代表整个数字长度,2代表小数位数的长度.
enum枚举类型:仅能选取其中已经有的 元素来存储,代表从一开始的数字
set集合类型:能从集合中选取多个元素进行存储——用户兴趣标签
set存储原理???
varchar和char类型? #
1.varchar 是可变⻓度的字符类型,原则上最多可以容纳 65535 个字符,但考虑字符集,以及 MySQL 需要 1 到2个字节来表示字符串⻓度,所以实际上最⼤可以设置到 65533。
2.char 是固定⻓度的字符类型,当定义⼀个 CHAR(10) 字段时,不管实际存储的字符⻓度是多少,都只会占⽤ 10个字符的空间。如果插⼊的数据⼩于 10 个字符,剩余的部分会⽤空格填充。
blob(Binary Large Object) and text #
1.blob⽤于存储⼆进制数据,⽐如图⽚、⾳频、视频、⽂件等;但实际开发中,我们都会把这些⽂件存储到 OSS 或者⽂件服务器上,然后在数据库中存储⽂件的 URL。 2.text ⽤于存储⽂本数据,⽐如⽂章、评论、⽇志等。
4.列属性完整性(重点) #
auto_increment 必须是 primarykey主键
primary key主键:唯一性 一组或者一个字段 #
1.保证数据的完整性,和一致性.
2.加快数据的查询速度—>用来做表的关联
alter table <tablename> add primary key (<filedname>......);
-- 添加主键,多个字段就是组合键
alter table <tablename> drop primary key;
-- 删除主键
复合主键解决的问题
unique唯一键
和primary的区别:可以为null,不和其他表产生关联,但是必须唯一(null不唯一)
alter table <tablename> drop index <filedname>;
comment 注释问题
SQL内注释和代码注释
数据库的完整性问题
Foreign Key(外键约束技术) #
怎么在两张表之间建立联系?
主表:
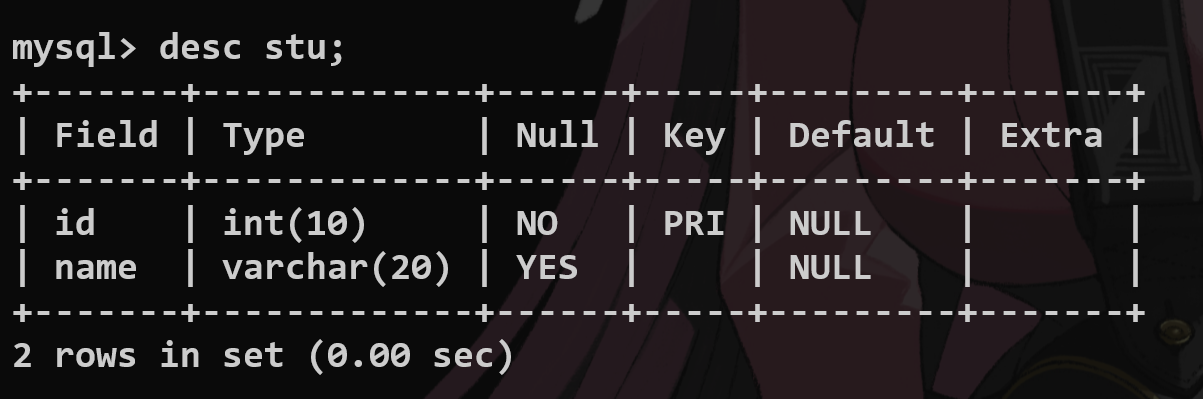
建立从表:—>创建的语法要注意.
这是物理外键:禁用,影响效率,容易引发死锁的问题.
实际开发中我们采用逻辑外键,在业务层面来解决问题.—>交给代码层面来处理?
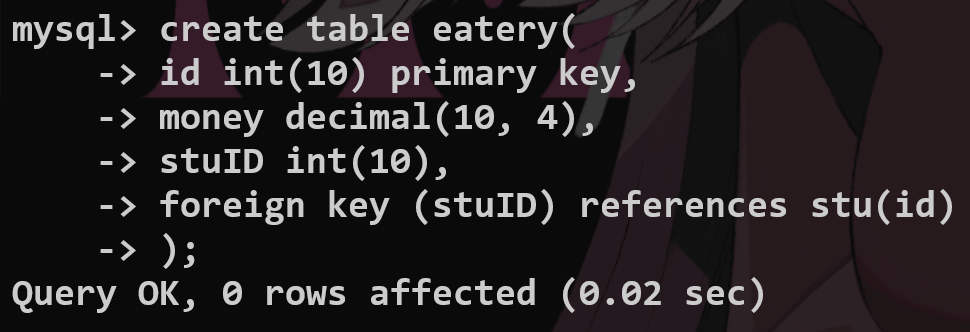
从表:
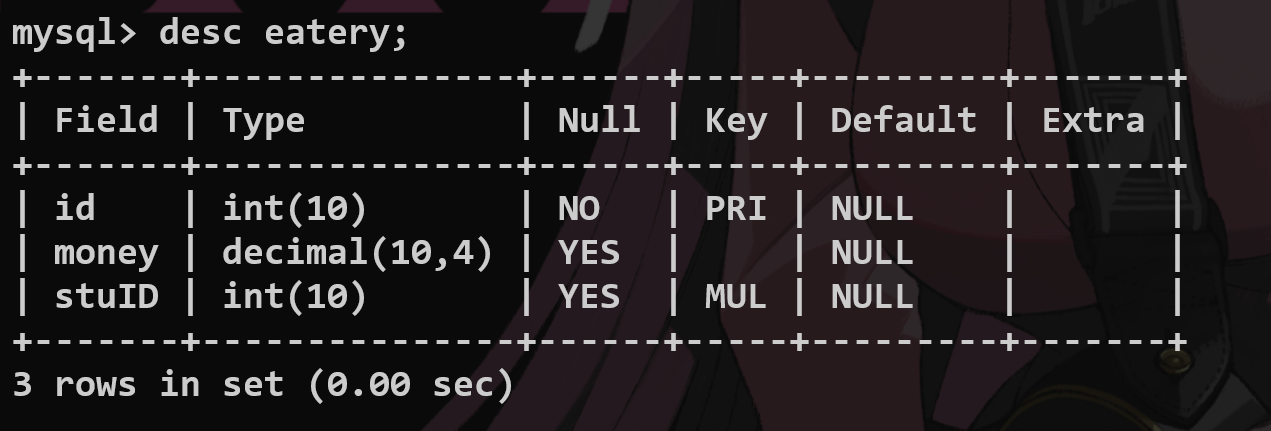
alter table <tablename> add foreign key (<filedname>) references <tablename>(<filedname>);
show create table <tablename>;
查看创建的表结构并且删除外键
当主表中的数据发生变化的时候,从表中的数据应该如何修改?
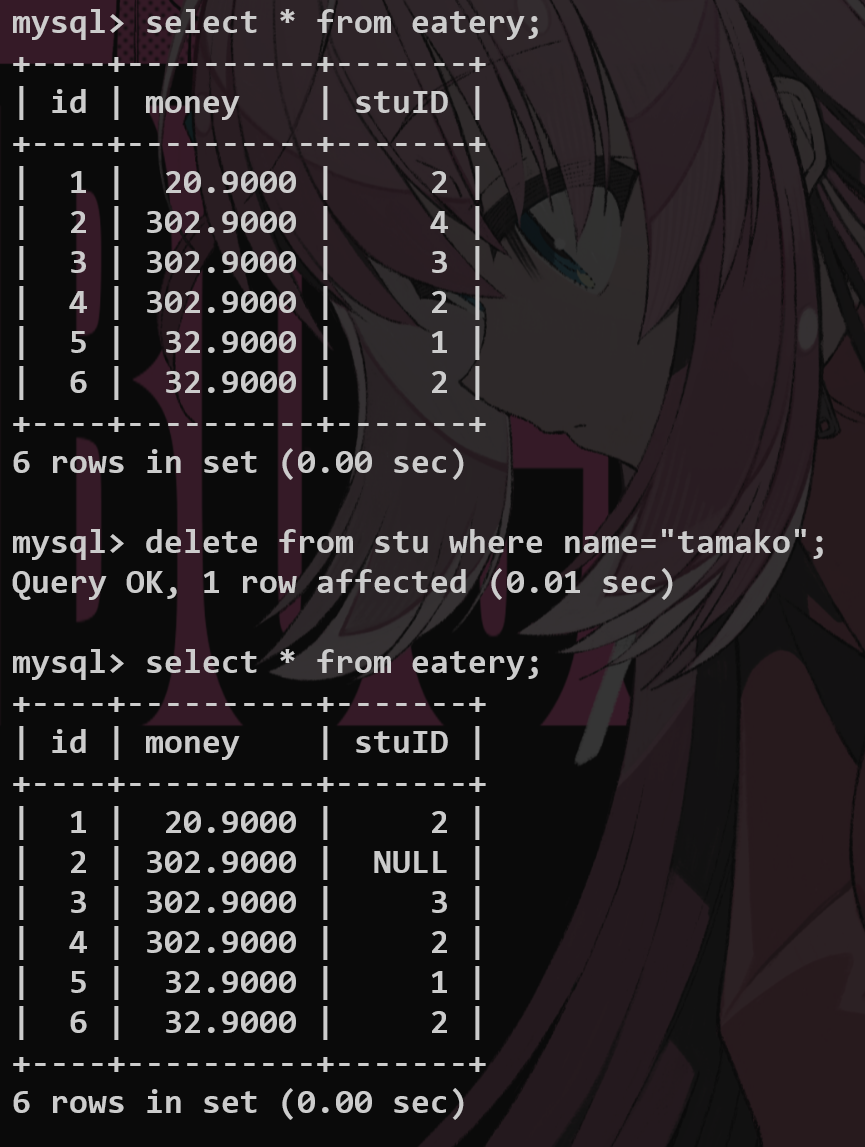
置空和级联的操作(在创建表的时候就要声明清楚) #
置空:主表中的数据被删除,那么从表中的数据依然保存,但是外键的被删除的字段为NULL;
级联:主表中的数据发生修改,从表中的外键对应字段的数据全部发生修改;

如图:删除——set null
5.数据库设计思维 #
分析业务模块之间的关系.—>这个设计可能是非常复杂的,我觉得实习生一般不会设计,项目应该会交给DBA?
a.基本概念 #
关系:两张表通过共同的字段来确立数据的完整性
行——一条数据——实体
列——一个字段——属性
数据冗余:牺牲空间,提升查询性能(高考总分)
b.实体之间的关系 #
一对多(学生表和食堂消费记录之间的关系)
一对一(比如用户和身份信息—>表拆分) 比如加入外键,关联主表的主键,然后把把这个外键设置成unique即可.
多对一(大学选课,建立中间表,建立两个外键关联双方的主键,相当于这个第三方表存放了这些选课的信息)
多对多
c.三大范式 #
原子性,比如地址要拆分成省市县之类的.
Codd第一范式:确保字段的原子性,一个字段不可以再分 2018-2019 —— 2018 2019
不加入无用的信息,我感觉这两个讲的是一个东西.
Codd第二范式:非键字段必须依赖于主键字段(无关的字段不应当加入,一张表只描述一种信息)
?查询信息的时候不能查询到冗余信息.
Codd第三范式:消除传递依赖——根据实际情况,我们到底要不要考虑加入数据冗余的处理
建表的时候要考虑什么? #
⾸先需要考虑表是否符合数据库的三⼤范式,确保字段不可再分,消除**⾮主键依赖**,确保字段仅依赖于主键等。 然后在选择字段类型时,应该尽量选择合适的数据类型。 在字符集上,尽量选择 utf8mb4,这样不仅可以⽀持中⽂和英⽂,还可以⽀持表情符号等。 当数据量较⼤时,⽐如上千万⾏数据,需要考虑分表。⽐如订单表,可以采⽤⽔平分表的⽅式来分散单表存储压⼒。
6.*单表查询 #
DQL,查询是SQL的重点问题,因为这也是BS软件操作中最为频繁的.
a.基本关键字 #
select #
比如说我们查看一张table的结构并且进行查找:
desc tb_emp;
select id, username, tb_emp.password from tb_emp;
select * from tb_emp;-- *返回所有的字段(不直观而且性能差(为什么?))
-- SQL解析* 要进行元数据的查找操作
select name as nickname, password as fucking_ps from tb_emp;-- 作为别名来返回
select distinct job from tb_emp;-- distinct去重
还有很多其余的用法
select查询语句的顺序? #
先执⾏ FROM 确定主表,再执⾏ JOIN 连接,然后 WHERE 进⾏过滤,接着 GROUP BY 进⾏分组,HAVING过滤聚合结果,SELECT 选择最终列,ORDER BY 排序,最后 LIMIT 限制返回⾏数。
WHERE 先执⾏是为了减少数据量,HAVING 只能过滤聚合数据,ORDER BY 必须在 SELECT 之后排序最终结果,LIMIT 最后执⾏以减少数据传输。
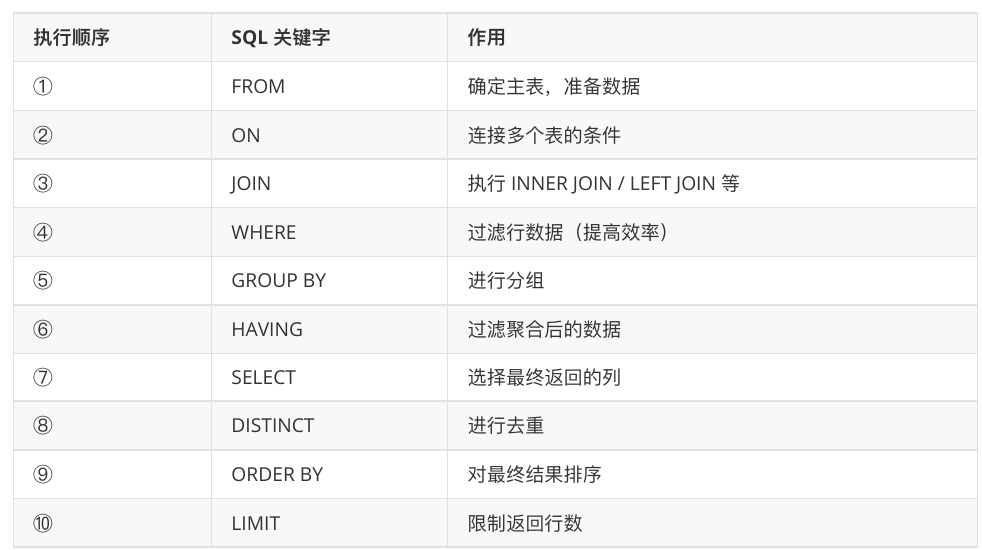
这个执⾏顺序与编写 SQL 语句的顺序不同,这也是为什么有时候在 SELECT ⼦句中定义的别名不能在 WHERE ⼦句中使⽤的原因,因为 WHERE 是在 SELECT 之前执⾏的.
LIMIT在最后执行:因为 LIMIT 是在最终结果集上执⾏的,如果在 WHERE 之前执⾏ LIMIT,那么就会先返回所有⾏,然后再进⾏LIMIT 限制,这样会增加数据传输的开销.
sql的隐式转换 #
MariaDB [(none)]> select 1 + 1.0;
+---------+
| 1 + 1.0 |
+---------+
| 2.0 |
+---------+
1 row in set (0.001 sec)
MariaDB [(none)]> select '1' + 2;
+---------+
| '1' + 2 |
+---------+
| 3 |
+---------+
1 row in set (0.000 sec)
整数转换成浮点数,字符串转换成整数.
SQL的语法树解析 #
SQL 语法树解析是将 SQL 查询语句转换成抽象语法树 —— AST 的过程,是数据库引擎处理查询的第⼀步,也是防⽌ SQL 注⼊的重要⼿段。
SELECT id, name FROM users WHERE age > 18;
1.拆解识别关键字:
[SELECT] [id] [,] [name] [FROM] [users] [WHERE] [age] [>] [18] [;]
2.构建抽象语法树.
SELECT
├── COLUMNS: id, name
├── FROM: users
├── WHERE
│ ├── CONDITION: age > 18
3.检查是否存在 + 权限验证
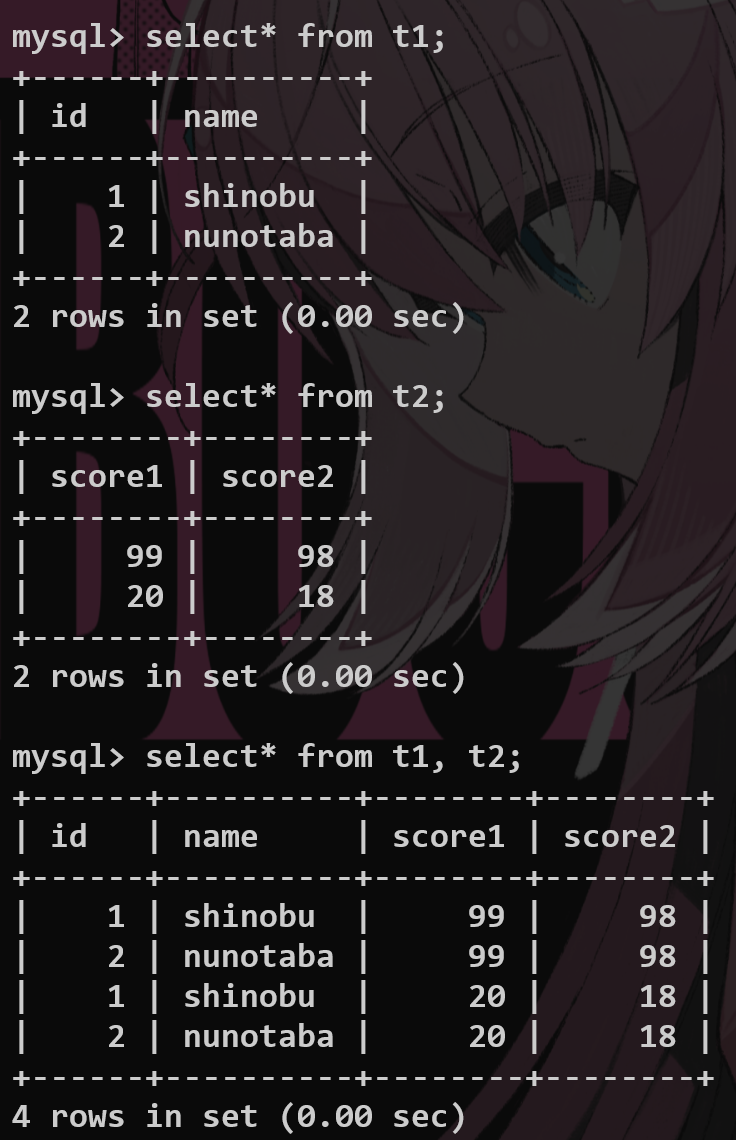
from #
指定要查的表;返回两张表的笛卡尔积
dual #
默认的一个虚拟表,单行单列
where #
限制select查询条件 < ≤ > ≥ or and……
举几个例子:
select * from tb_emp where id = 3;
select * from tb_emp where id <= 5;
select * from tb_emp where job is null;-- 判断是否有值 要用is null/ is not null
select * from tb_emp where job is not null;
select * from tb_emp where password != '123456';
select * from tb_emp where entrydate >= '2000-01-01' and entrydate <= '2010-01-01';
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01';-- 限定日期的范围
select * from tb_emp where job in (2, 3, 4);
select * from tb_emp where name like '__';-- 模糊匹配 _匹配一个字符 %匹配任意字符
select * from tb_emp where name like '张%';
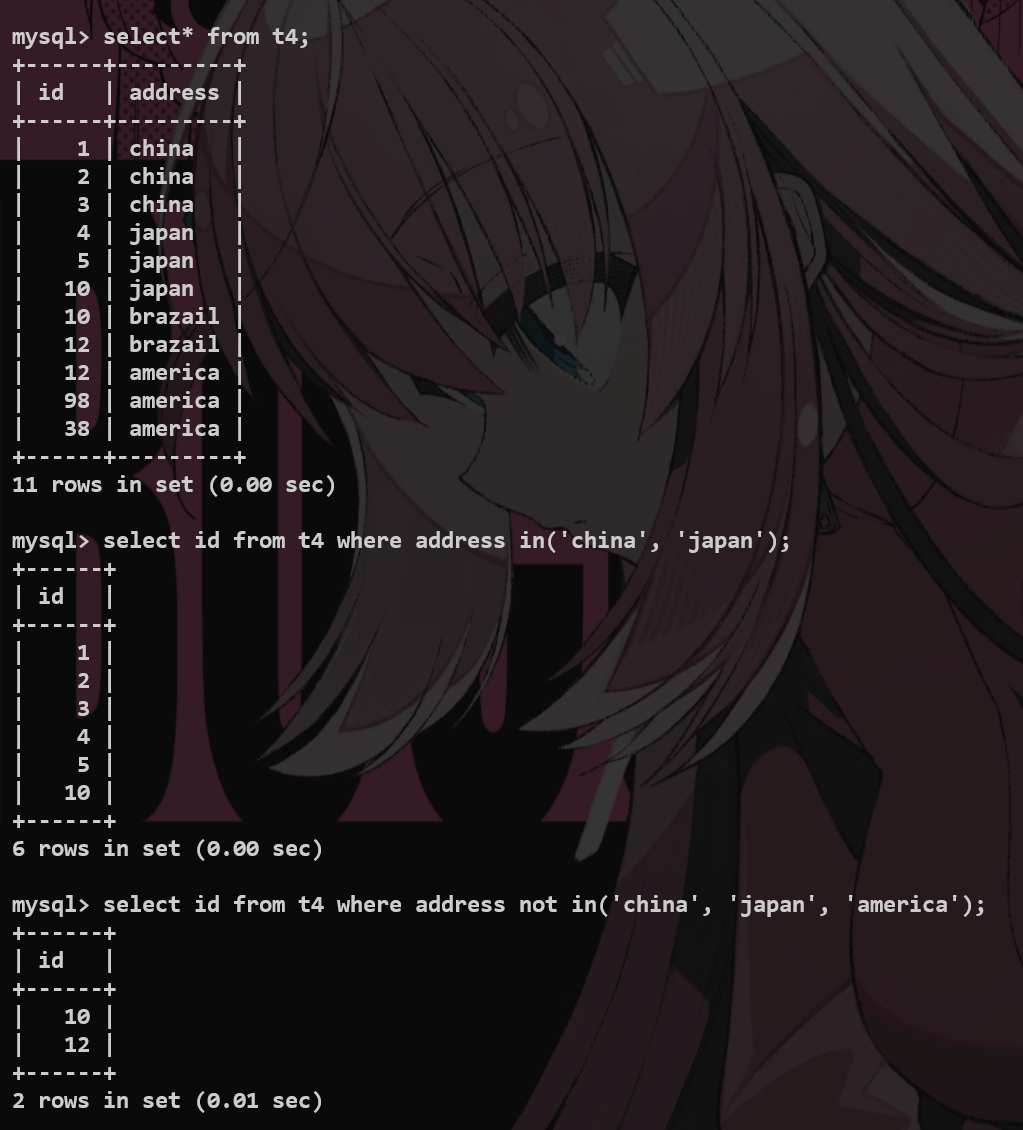
in #
限定查询的字段的值在一个范围之内
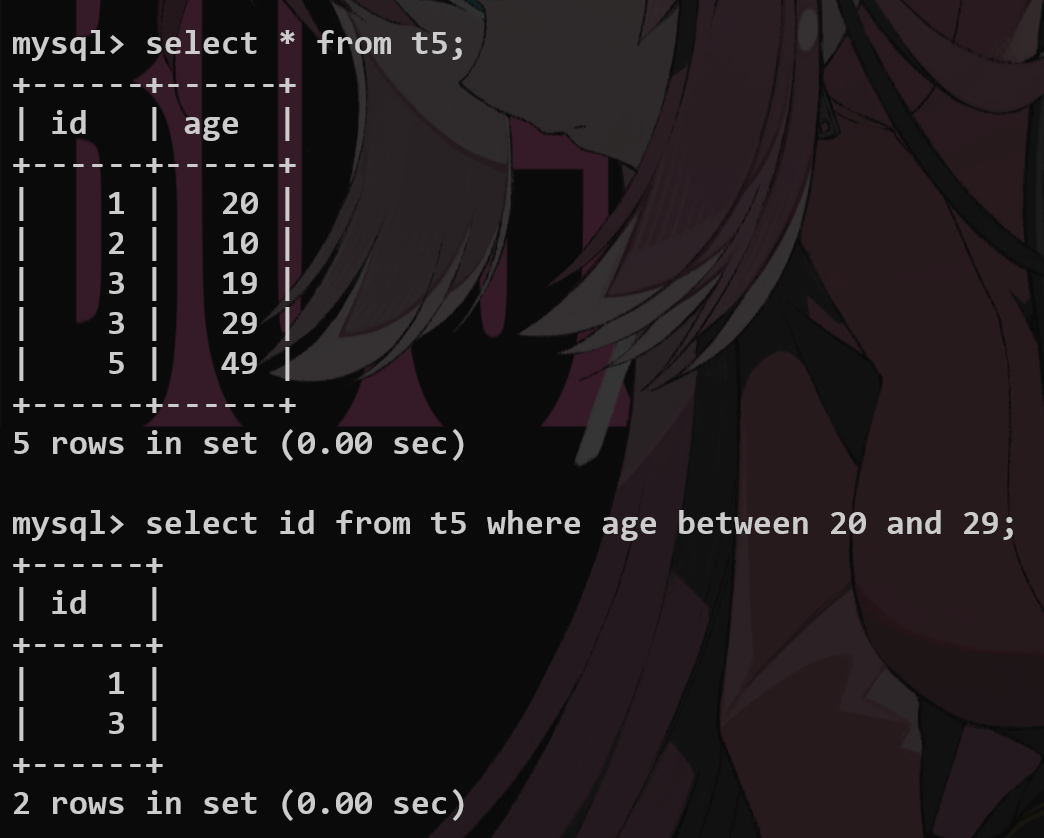
between…and… #
限制查询的范围在给定的闭区间内部
is null #
查看是空或者非空,简单
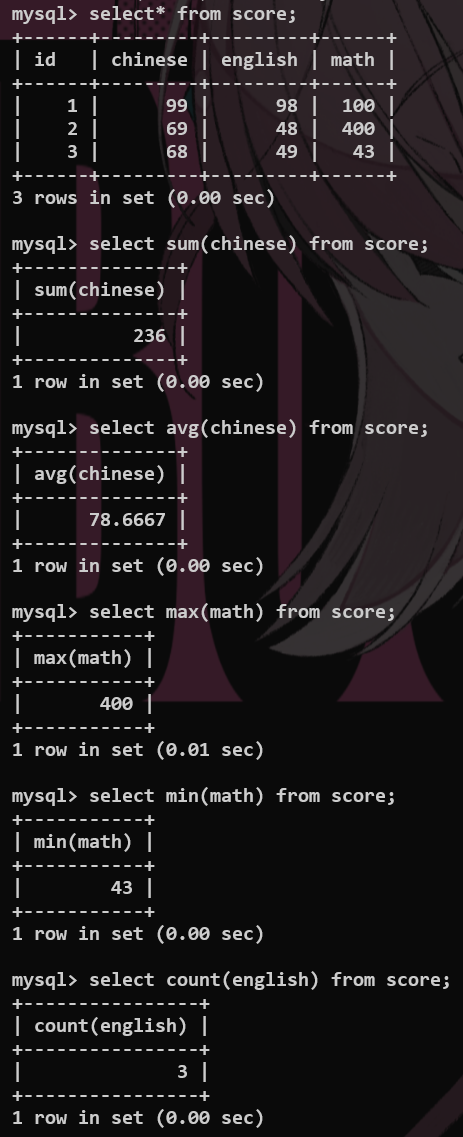
*几种常见的聚合函数 #
count max min avg sum
-- count 1.数量统计 2.count(常量) 3.count(*)
select count(id) from tb_emp;
select count(distinct job) from tb_emp;-- 不重复的工作种类
select count(114514);
select count(*) from tb_emp;-- 推荐使用这个*,底层进行了优化的处理.
-- min max 选取极值
select min(tb_emp.entrydate) from tb_emp;
select max(tb_emp.entrydate) from tb_emp;
select avg(tb_emp.id) from tb_emp;
select sum(id) from tb_emp;
[!TIP]
**Q:select count(*) and select count(1); **
what’s the difference?
在 InnoDB 引擎中, COUNT(1) 和 COUNT(*) 没有区别,都是⽤来统计所有⾏,包括 NULL。 如果表有索引, COUNT(*) 会直接⽤索引统计,⽽不是全表扫描,⽽ COUNT(1) 也会被 MySQL 优化为COUNT(*) 。COUNT(列名) 只统计列名不为 NULL 的⾏数。
另外,MySQL 8.0 官⽅⼿册有明确说明,InnoDB 引擎对 SELECT COUNT(*) 和 SELECT COUNT(1) 的处理⽅式完全⼀致,性能并⽆差异。
like模糊查询——通配符 #
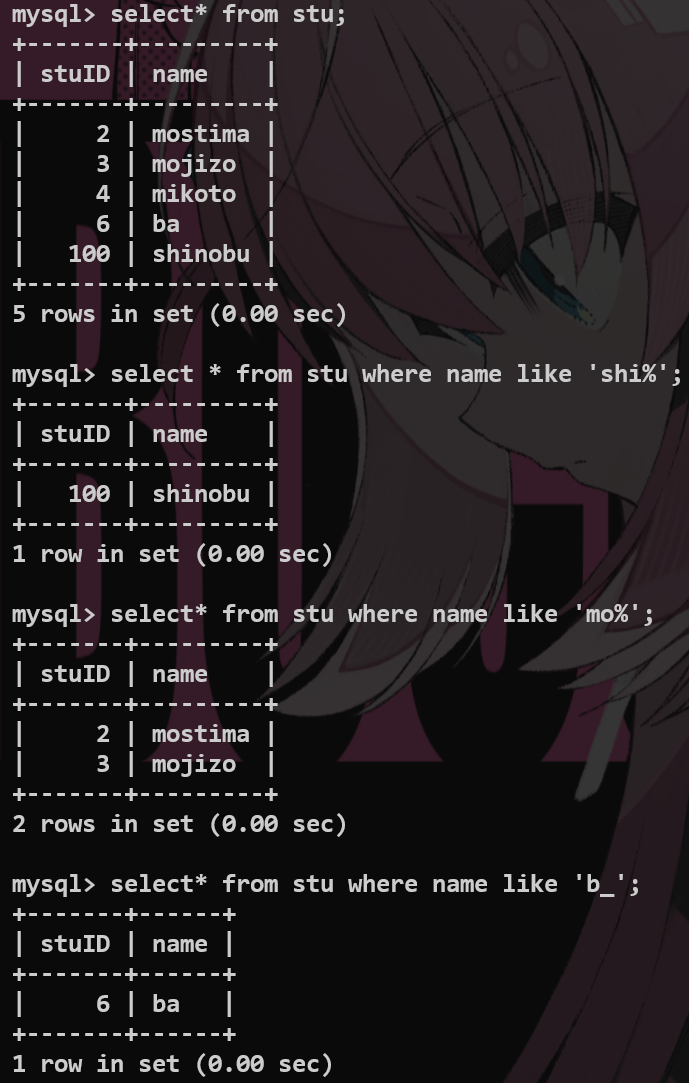
group by 分组查询 #
不抽象,其实就是根据某个字段来进行分组.
将某一列数据作为一个整体来进行纵向的计算.
select <function-name>(<fieldname1>) as 'alias1', <fieldname2> as 'alias2' group by <fieldname2>;-- 要根据哪个字段去查询
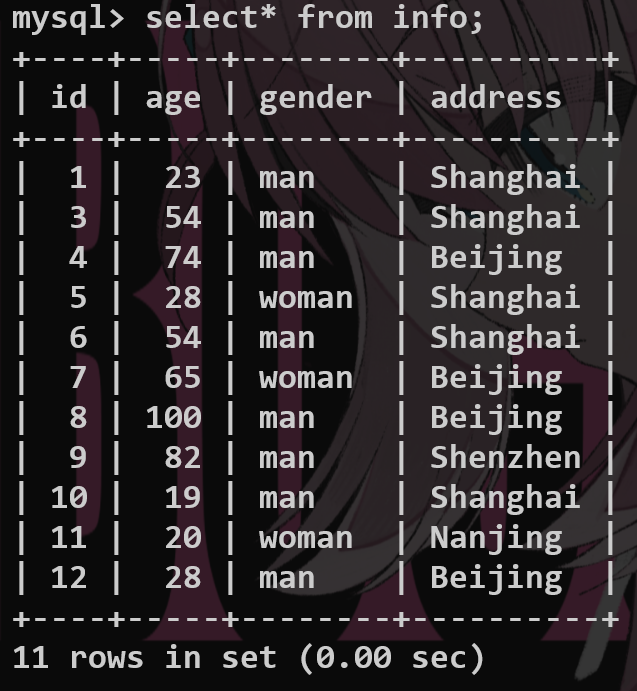
比如想求男性和女性的平均年龄:
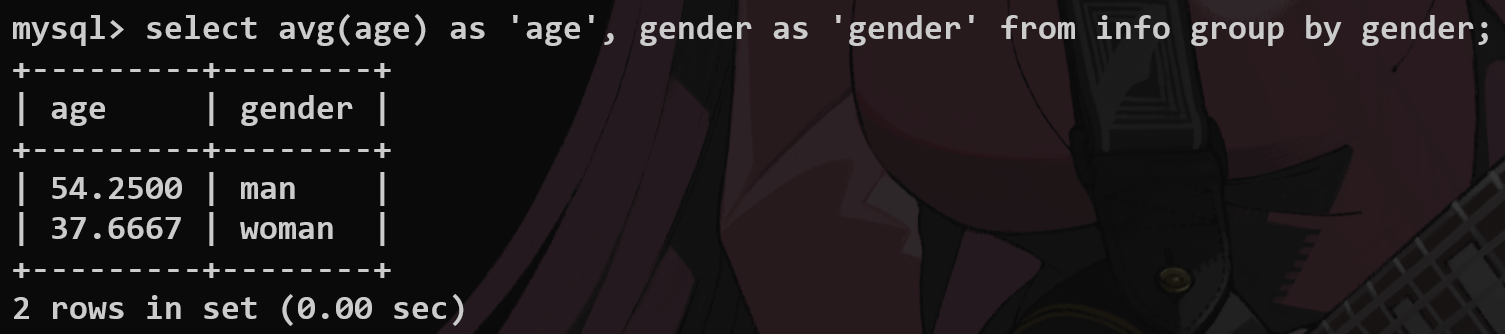
利用group_concat函数查询对应字段对应的实体
进行一些比较复杂的查询:
select count(*) as 'number' ,tb_emp.gender as 'gender' from tb_emp group by gender;
select job as 'job', count(*) as 'number' from tb_emp where entrydate <= '2015-01-01' group by job having number >= 2;
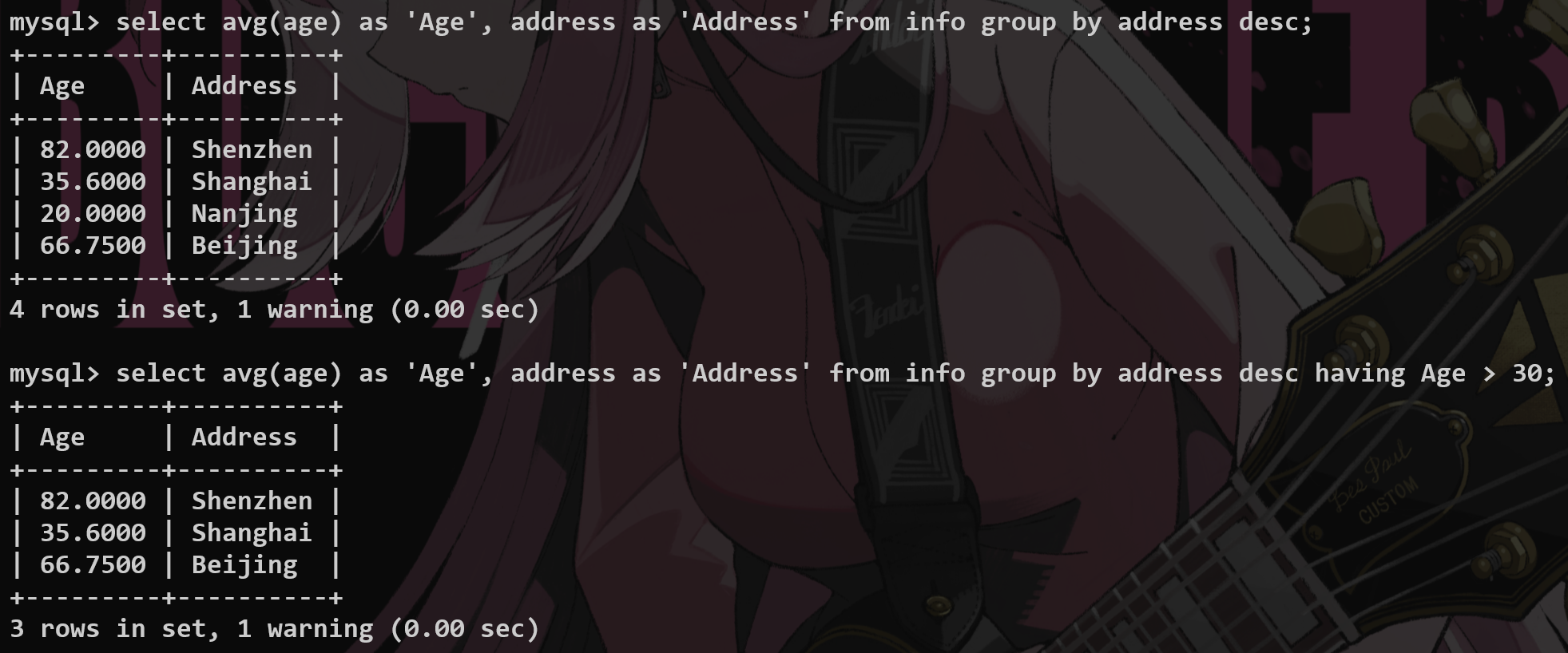
having #
就是用聚合函数来过滤分组之后产生的数据.
| 特性 | WHERE 子句 | HAVING 子句 |
|---|---|---|
| 执行阶段 | 在数据分组之前执行。 | 在数据分组之后、聚合函数计算完毕后执行。 |
| 作用对象 | 作用于原始表中的行。 | 作用于 GROUP BY 产生的组。 |
| 可否使用聚合函数 | 不能直接使用聚合函数进行过滤。 | 必须使用聚合函数或分组字段进行过滤。 |
和where一样作为条件筛选,但是:
1.where是根据条件对于实际存在于数据库中的数据进行筛选
分组之前where先进行一次过滤,分组之后having再进行过滤.
2.having对于查询之后的虚拟表使用——比如配合group_by(此时就不能使用where条件来处理)
where不能对聚合函数进行作用.
order by #
排序的函数.
asc升序,desc降序.
select * from tb_emp order by entrydate asc, update_time desc;
前一个字段的值相同的时候才会进行下一个字段的排序.
*limit #
选取顺序中的下标范围
比如实现用户界面的分页条,就利用limit来进行查询.—>分页查询.
有点重点是因为是分页查询的实现原理.
select <fieldname> from <tablename> limit <start-index>,<length>;
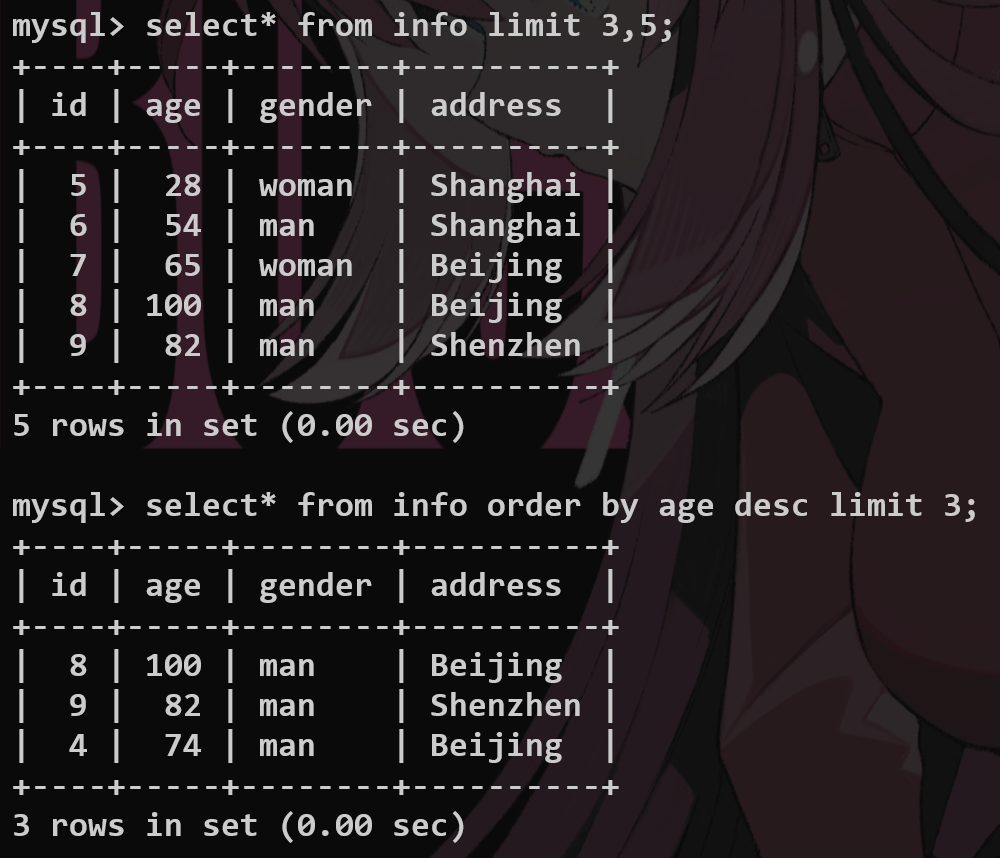
select * from tb_emp limit 5;-- 忽略起始索引.
select * from tb_emp limit 5, 5;-- 直接计算起始索引,要进行页码的换算.
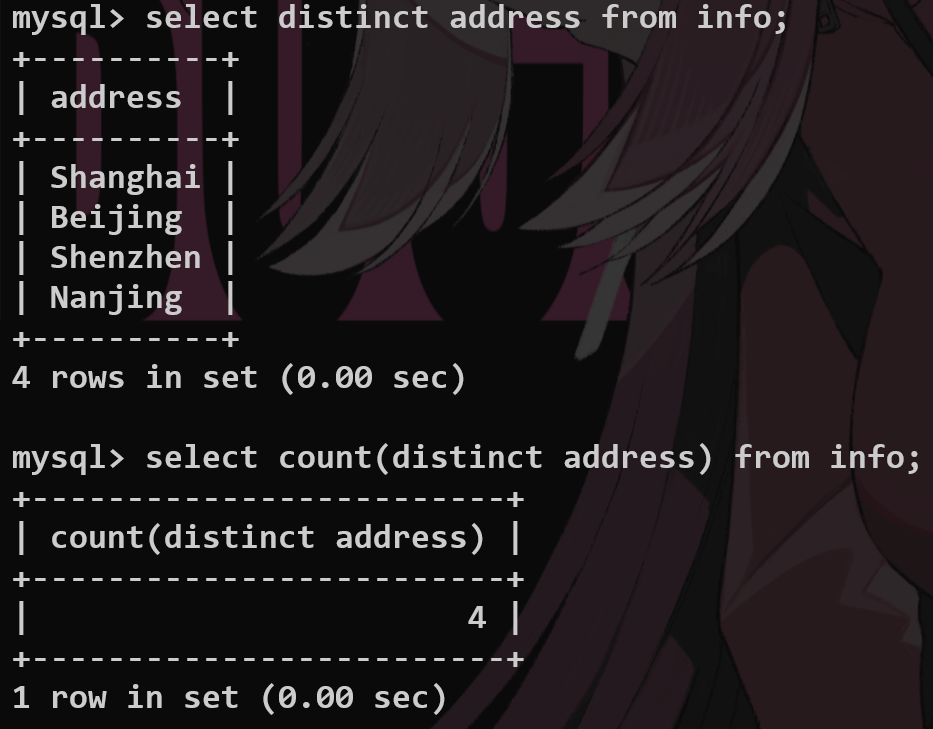
distinct #
去重复关键字
默认情况下有all
select (all) <fieldname> from <tablename>;
至此,单表查询基础结束。
一些组合查询:
流程控制函数,基本查询.
select * from tb_emp where name like '张%' and gender = 1 and (entrydate >= '2000-01-01' and entrydate <= '2015-12-31') order by update_time desc limit 10;
-- 利用流程函数if来进行展示
select if(tb_emp.gender = 1, 'Male', 'Female') as 'Gender', count(*) as 'Number'
from tb_emp
group by gender;
-- case控制
select case job when 1 then 'Sensei' when 2 then 'Mamiko' when 3 then 'Bro' else 'GOGOGO' end as 'Job',
count(*) as 'Number'
from tb_emp
group by job;
7.多表查询 #
就是从多张表中进行连接式的查询.
1.union #
select… + union + DISTINCT + select…
对应字段个数必须相等
2.join #
内连接 #
这都是内连接的方式:
-- 这是隐式的内连接
select tb_emp.name, tb_dept.name from tb_emp,tb_dept where tb_emp.dept_id = tb_dept.id;
-- 这是显式的内连接
select tb_emp.name, tb_dept.name from tb_emp inner join tb_dept on tb_emp.dept_id = tb_dept.id;
用两个表创建公共字段进行连接——内连接——有多张表就用多个inner进行连接
内连接仅查询共有的数据.
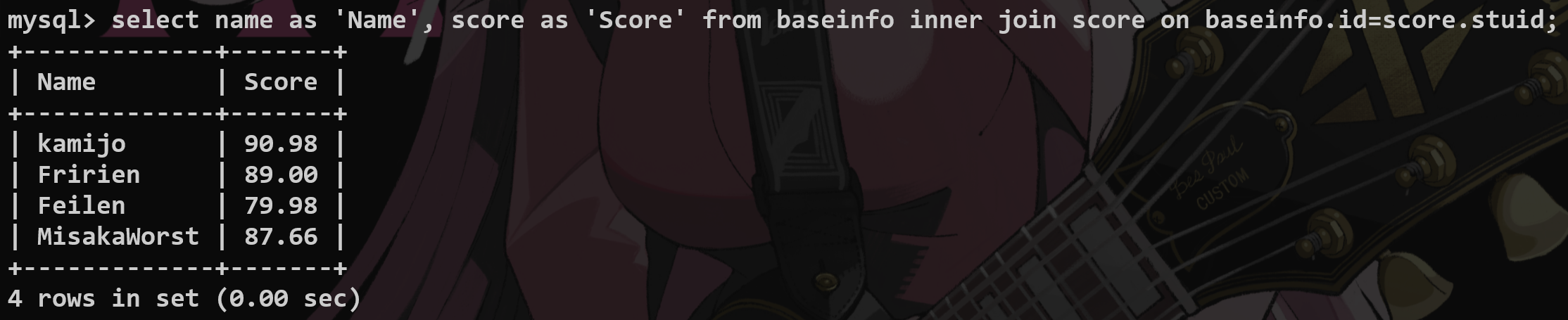
select f1,f2 from t1 inner join t2 on t1.f3=t2.f4 (having score > 90);
left join 以左表为一个基准(就算左边没有也要写上去 right join 同理)—>意思就是完全包含左表的数据.
这个意思就是即使左边没有部门,我们也会把这一行给列出来.
你可以直接把这里的左右想象成物理上的左右连接.
select tb_emp.name as 'empName', tb_dept.name as 'depName' from tb_emp left outer join tb_dept on tb_emp.dept_id = tb_dept.id;

cross join返回两张表的笛卡尔积—>增加条件的目的就是消除无效的笛卡尔积.
select* from t1 cross join t2;
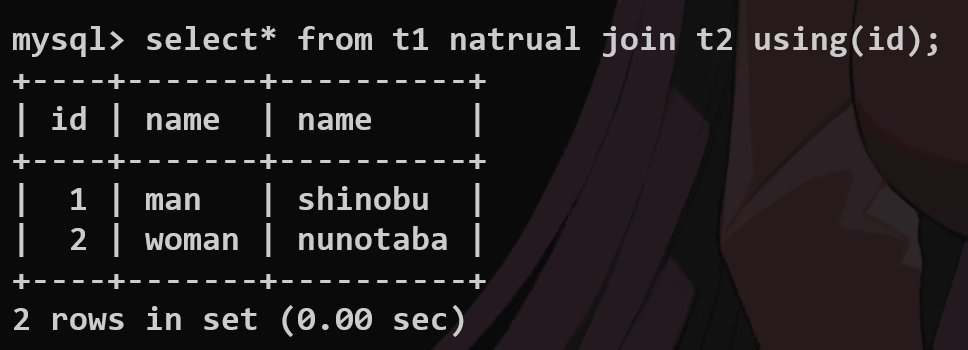
natural join自动寻找公共字段并且建立inner join的连接
没有公共字段就返回cross join的结果
using
当两张表的字段完全相同的时候,using指定建立连接的公共字段
8.子查询 #
用一个select语句返回的数据范围作为限制的基准(用in和not in 来控制)
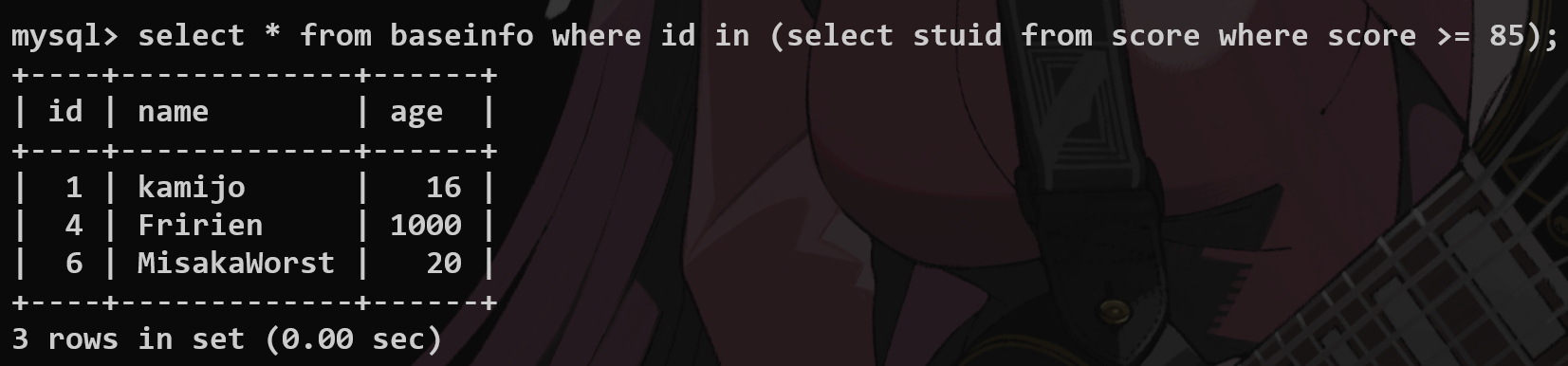
只要存在就全部查询 exists and not exists
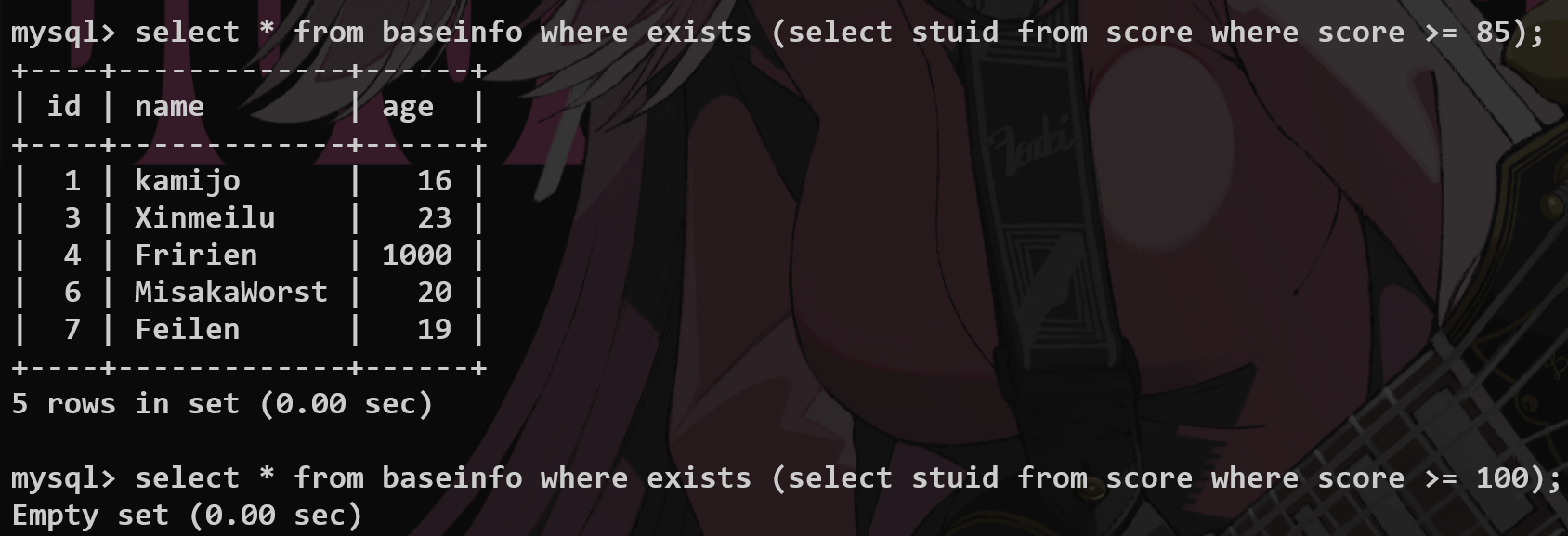
in和exists的区别? #
当使⽤ IN 时,MySQL 会⾸先执⾏⼦查询,然后将⼦查询的结果集⽤于外部查询的条件。这意味着⼦查询的结果集需要全部加载到内存中。 ⽽ EXISTS 会对外部查询的每⼀⾏,执⾏⼀次⼦查询。如果⼦查询返回任何⾏,则 EXISTS 条件为真。 EXISTS 关注的是⼦查询是否返回⾏,⽽不是返回的具体值。
IN 适⽤于**⼦查询结果集较⼩的情况。如果⼦查询返回⼤量数据**, IN 的性能可能会下降,因为它需要将整个结果集加载到内存。 ⽽ EXISTS 适⽤于**⼦查询结果集可能很⼤的情况**。由于 EXISTS 只需要判断**⼦查询是否返回⾏,⽽不需要加载整个结果集,因此在某些情况下性能更好,特别是当⼦查询可以使⽤索引**时。
NULL值的问题 #
IN : 如果⼦查询的结果集中包含 NULL 值,可能会导致意外的结果。例如, WHERE column IN (subquery) ,如果 subquery 返回 NULL ,则 column IN (subquery) 永远不会为真,除⾮ column 本身也为 NULL 。 EXISTS : 对 NULL 值的处理更加直接。 EXISTS 只是检查⼦查询是否返回⾏,不关⼼⾏的具体值,因此不受 NULL值的影响。
举几个很好的例子:
-- 子查询
-- 1.标量子查询,查询只会返回一个结果,比如查询一个部门的所有员工(一行一列)
select * from tb_emp where tb_emp.dept_id = (select id from tb_dept where tb_dept.name = '教研部');
-- 2.列子查询,返回一列的数据,in判断是不是在这一列数据内部
select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部');
-- 3.行子查询,返回的是一行的数据,可以有多列,怎么对齐--->查询的时候采用组合字段处理
select * from tb_emp where (entrydate, job) = (select entrydate, job from tb_emp where name = '韦一笑');
-- 4.表子查询,把查询的表作为临时表再次进行查询
select e.name as 'empName', d.name as 'deptName' from (select * from tb_emp where entrydate > '2006-01-01') e, tb_dept d where e.dept_id = d.id;
至此,所有基础内容结束,以上的内容都是对于一名实习生来说最为重要的内容(每一种语法单独看来都是很好理解的,但是都联合起来的话就显得很困难),以下为扩展,但是大厂应该问的比较多.
*扩展内容: #
1.视图(View) #
作用:简化SQL查询;掩盖敏感数据
创建视图

以后就可以直接查询
alter修改视图
drop直接删除视图
视图底层算法(在使用子查询创建视图的时候)
unchecked
1.temp table 临时表算法
2.merge 合并算法
2.*事务(Transaction) #
处理非常严谨的操作,例如转账等
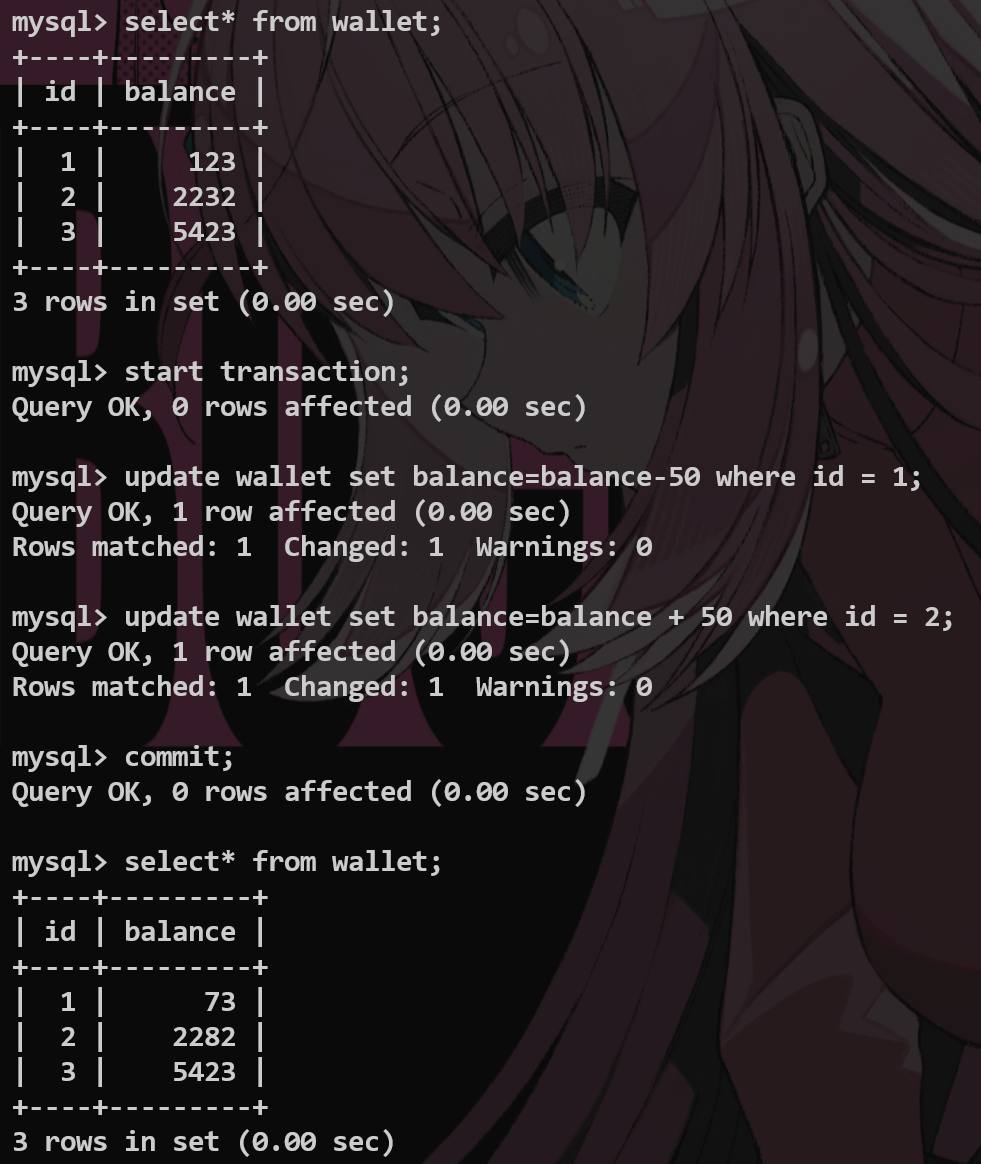
设置回滚点 并且返回—— rollback to
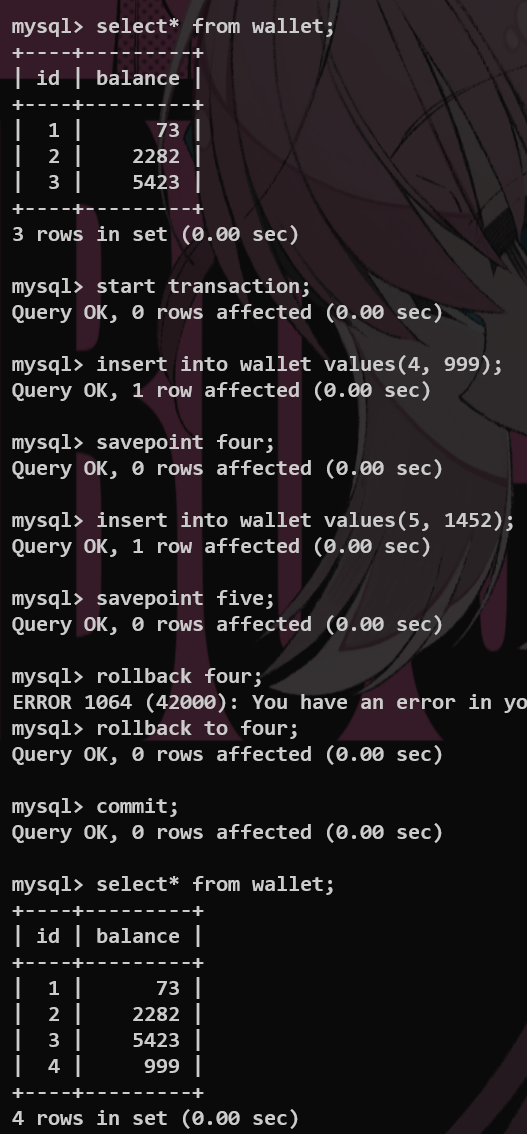
Atomicity 原子性:一个事务不可再分,要么全部执行,要么不执行
Consistensy 一致性:事务提交之后,数据库的完整性没有被破坏
Isolation 隔离性:多个事务同时对一个数据库进行操作,不会产生冲突
Duration 持久性:一旦提交,对于数据库的更改是永久的
注意:仅当engine=innodb的时候,才能使用事务
3.index(索引) #
索引的目的就是高效地获取数据.
快速查询数据——实习生要理解到什么程度?
没有建立index之前,我们要对于整张表进行扫描才能查找到对应的数据.
遍历整张表,根据索引排列构建一个二叉搜索树,以后在查找的时候,对于这个树进行查找即可.
这样的建立提升了查询和排序的效率.
但是建立了这样的树形结构,会占用存储空间,降低了update insert delete的效率.—>要维护数据的索引结构,所以是否要建立要根据表本身的用途.
数据结构 #
复习一下基本数据结构.
这里基本都是B+树.—>多路平衡搜索树,没那么难.
如果仅有两个节点的话,层数会很深,检索会变慢.
简单的语法:
-- 创建索引index
create unique index idx_emp_name on tb_emp(name);
-- 查询索引的信息
show index from tb_emp;
-- 创建主键就会自动生成索引--->主键索引,性能是最高的
-- 唯一约束--->唯一索引
-- 怎么删除一个index索引
drop index idx_emp_name on tb_emp;
4.存储过程 #
提前写好SQL一次执行,有点像函数
利用delimiter设置结束符号
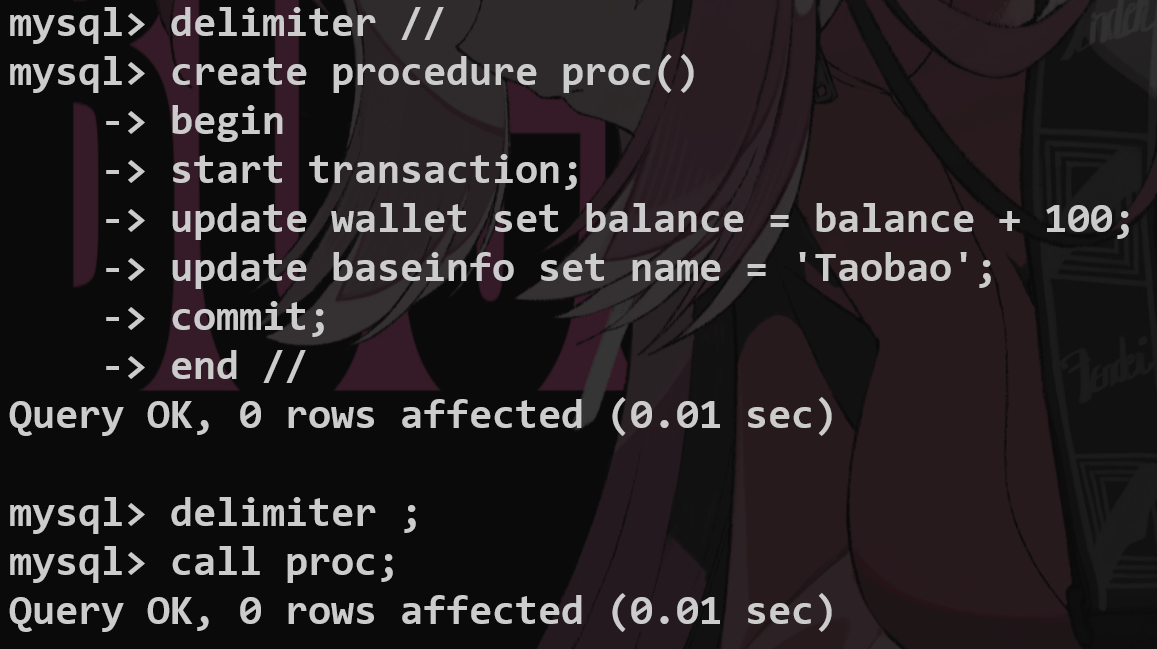
企业规范约束 #
1.库表字段的约束规范 #
是否: is_vip unsigned tiny int length1️⃣ (不能浪费存储)
dont’s
不能有大写字母,
不能以数字开头,
下划线之间不能只有数字,
不能出现负数,
不能有关键字
凡是有小数,必须用decimal数据类型
dos
主键:pk_key,
字符串长度较小时,请使用char,
强制存在的字段:
1.id(unsigned bigint 单表的时候必须自增 primary key)
2.create_time(datetime)
3.update_time(datatime),
2.索引规范 #
有某些必须:唯一索引
不能查两个以上的关联查询
varchar上建立索引:建立索引的长度
3.SQL开发约束 #
count(xx,xxx,xx) count(*);
判断为空的方法:
where name = null ;
where name is null;
不要使用外键和级联(尤其是在高并发的项目中,牵一发而动全身)
这些问题在Server层解决
不允许使用存储过程(很难调试,其中的SQL写错了怎么办,和脚本不一样,移植性也很差)
utf-8作为标准编码格式
4.其他约束 #
ORM框架查询不能写*
Q:pujo类(最基础的java类)bool类型不能加is?
*Mysql基本架构 #
三层架构 #
①、连接层主要负责客户端连接的管理,包括验证⽤户身份、权限校验、连接管理等。可以通过数据库连接池来提升连接的处理效率。 ②、服务层是 MySQL 的核⼼,主要负责查询解析、优化、执⾏等操作。在这⼀层,SQL 语句会经过解析、优化器优化,然后转发到存储引擎执⾏,并返回结果。这⼀层包含查询解析器、优化器、执⾏计划⽣成器、⽇志模块等。 ③、存储引擎层负责数据的实际存储和提取。MySQL ⽀持多种存储引擎,如 InnoDB、MyISAM、Memory 等。
binlog 在服务层,负责记录 SQL 语句的变化。它记录了所有对数据库进⾏更改的操作,⽤于数据恢复、主从复制等。
也就是log日志系统来辅助恢复.
udpate原理 #
⼀条 UPDATE 语句的执⾏过程包括读取数据⻚、加锁解锁、事务提交、⽇志记录等多个步骤。
1.记录undo log,用于回滚.
2.存储引擎还会将更新操作写⼊ redo log,状态标记为 prepare,并确保 redo log 持久化到磁盘。这⼀步可以保证即使系统崩溃,数据也能通过 redo log 恢复到⼀致状态。
3.写完 redo log 后,MySQL 会获取⾏锁,将 a 的值修改为 1,标记为脏⻚,此时数据仍然在内存的 buffer pool中,不会⽴即写⼊磁盘。后台线程会在适当的时候将脏⻚刷盘,以提⾼性能。
4.最后提交事务,redo log 中的记录被标记为 committed,⾏锁释放。
段区页行 #
MySQL 是以表的形式存储数据的,⽽表空间的结构则由**段、区、⻚、⾏**组成。
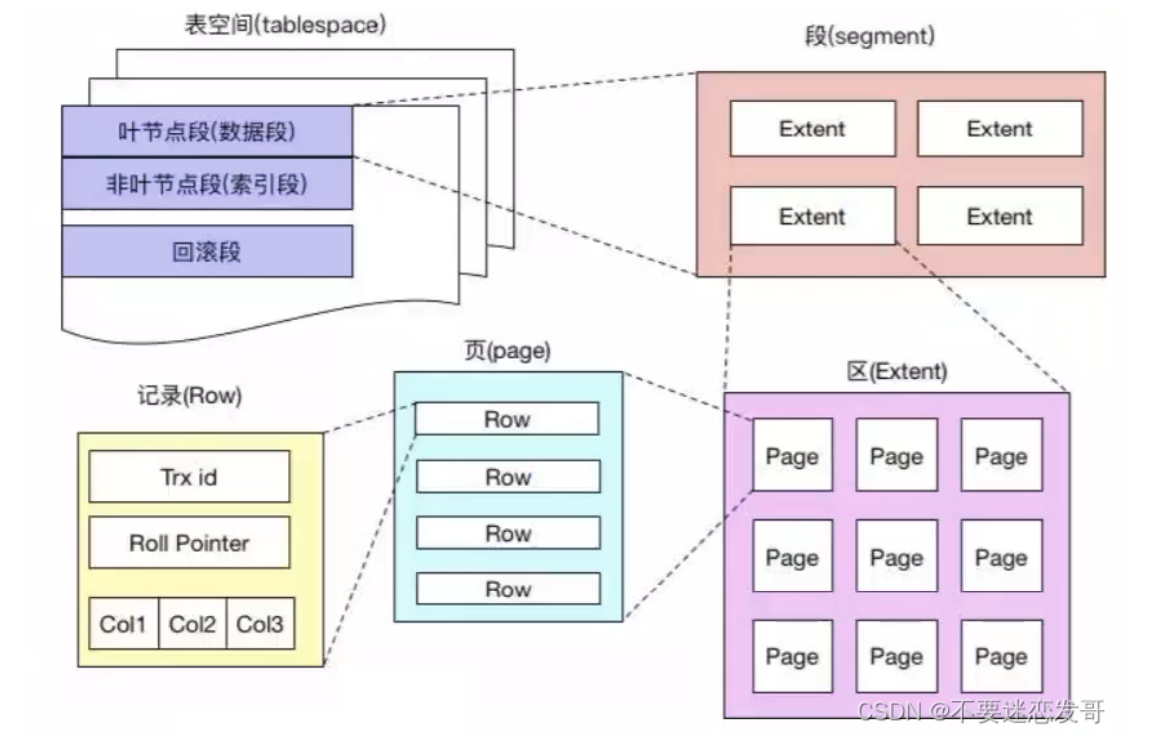
①、段:表空间由多个段组成,常⻅的段有数据段、索引段、回滚段等。创建索引时会创建两个段,数据段和索引段,**数据段⽤来存储叶⼦节点中的数据;索引段⽤来存储⾮叶⼦节点的数据。**回滚段包含了事务执⾏过程中⽤于数据回滚的旧数据。 ②、区:段由⼀个或多个区组成,区是⼀组连续的⻚,通常包含 64 个连续的⻚,也就是 1M 的数据。使⽤区⽽⾮单独的⻚进⾏数据分配可以优化磁盘操作,减少磁盘寻道时间,特别是在⼤量数据进⾏读写时。 ③、⻚:⻚是 InnoDB 存储数据的基本单元,标准⼤⼩为 16 KB,索引树上的⼀个节点就是⼀个⻚。也就意味着数据库每次读写都是以 16 KB 为单位的,⼀次最少从磁盘中读取 16KB 的数据到内存,⼀次最少写⼊16KB 的数据到磁盘。 ④、⾏:InnoDB 采⽤⾏存储⽅式,意味着数据按照⾏进⾏组织和管理,⾏数据可能有多个格式,⽐如说COMPACT、REDUNDANT、DYNAMIC 等。MySQL 8.0 默认的⾏格式是 DYNAMIC,由COMPACT 演变⽽来,意味着这些数据如果超过了⻚内联存储的限制,则会被存储在溢出⻚中。
理论上来说,你的数据是不能超过一整个page的大小,否则一定会造成行溢出的现象.
*常见存储引擎 #
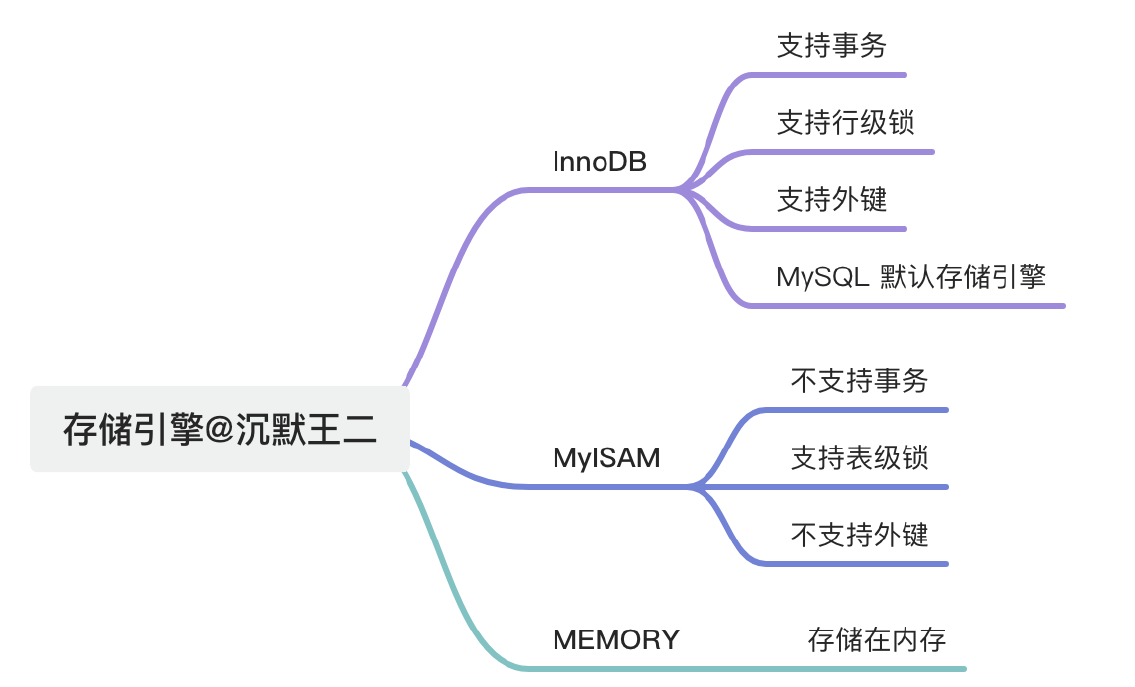
记住 MyISAM 不支持 外键 + 事务.
nnoDB 和 MyISAM 的最⼤区别在于事务⽀持和锁机制。InnoDB ⽀持事务、⾏级锁,适合⼤多数业务系统;⽽MyISAM 不⽀持事务,⽤的是表锁,查询快但写⼊性能差,适合读多写少的场景。
在你创建表之前就应当指定这个引擎:
MariaDB [db01]> create table man(
-> id int primary key
-> )engine=myisam;
Query OK, 0 rows affected (0.032 sec)
怎么选择存储引擎? #
⼤多数情况下,使⽤默认的 InnoDB 就可以了,InnoDB 可以提供事务、⾏级锁、外键、B+ 树索引等能⼒。 MyISAM 适合读多写少的场景。 MEMORY 适合临时表,数据量不⼤的情况。因为数据都存放在内存,所以速度⾮常快。
InnoDB的内存结构 #
InnoDB 的内存区域主要有两块,buffer pool 和 log buffer。
buffer pool ⽤于缓存数据⻚和索引⻚,提升读写性能;—>就是B+树
了解buffer pool么?
Buffer Pool 是 InnoDB 存储引擎中的⼀个内存缓冲区,它会将经常使⽤的**数据⻚、索引⻚**加载进内存,读的时候先查询 Buffer Pool,如果命中就不⽤访问磁盘了。
其实也就是我们实现的page cache,没什么特殊的.
log buffer ⽤于缓存 redo log,提升写⼊性能。—>就是日志的缓存.
针对于一个数据页的结构 #
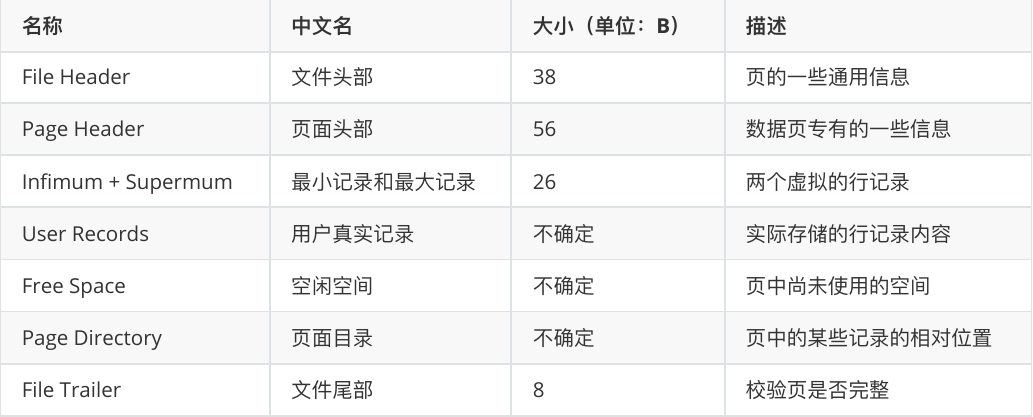
数据页的File Header都有指向上一个page或者下一个page的编号,构成一个双向的链表.
InnoDB 对 LRU 算法的优化了解吗? #
了解,InnoDB 对 LRU 算法进⾏了改良,最近访问的数据并不直接放到 LRU 链表的头部,⽽是放在⼀个叫midpoiont 的位置。默认情况下,midpoint 位于 LRU 列表的 5/8 处。
放到头部有可能导致cache抖动?
比如一次扫描了整个page,热点数据反而会被刷掉.
但是放在中间,就表明我要进行一些"观察",真的是,就会被自然放到最前方.
*log文件 #
有哪些log文件? #
有 6 ⼤类,其中错误⽇志⽤于问题诊断,慢查询⽇志⽤于 SQL 性能分析,general log ⽤于记录所有的 SQL 语句,binlog ⽤于主从复制和数据恢复,redo log ⽤于保证事务持久性,undo log ⽤于事务回滚和 MVCC。
①、错误⽇志(Error Log):记录 MySQL 服务器启动、运⾏或停⽌时出现的问题。 ②、慢查询⽇志(Slow Query Log):记录执⾏时间超过 long_query_time 值的所有 SQL 语句。这个时间值是可配置的,默认情况下,慢查询⽇志功能是关闭的。 ③、⼀般查询⽇志(General Query Log):记录 MySQL 服务器的启动关闭信息,客户端的连接信息,以及更新、查询的 SQL 语句等。 ④、⼆进制⽇志(Binary Log):记录所有修改数据库状态的 SQL 语句,以及每个语句的执⾏时间,如 INSERT、UPDATE、DELETE 等,但不包括 SELECT 和 SHOW 这类的操作。 ⑤、重做⽇志(Redo Log):记录对于 InnoDB 表的每个写操作,不是 SQL 级别的,⽽是物理级别的,主要⽤于崩溃恢复。 ⑥、回滚⽇志(Undo Log,或者叫事务⽇志):记录数据被修改前的值,⽤于事务的回滚以及MVCC的处理,因为多线程访问的时候,RC会返回旧版本.
我们重点理解一下binLog #
binlog 是⼀种物理⽇志,会在磁盘上记录数据库的所有修改操作。 如果误删了数据,就可以使⽤ binlog 进⾏回退到误删之前的状态。
# 步骤1:恢复全量备份
mysql -u root -p < full_backup.sql
# 步骤2:应⽤Binlog到指定时间点
mysqlbinlog --start-datetime="2025-03-13 14:00:00" --stop-datetime="2025-03-13 15:00:00"
binlog.000001 | mysql -u root -p
如果要搭建主从复制,就可以让从库定时读取主库的 binlog。
MySQL 提供了三种格式的 binlog:Statement、Row 和 Mixed,分别对应 SQL 语句级别、⾏级别和混合级别,默认为⾏级别。
从后缀名上来看,binlog ⽂件分为两类:以 .index 结尾的索引⽂件,以 .00000* 结尾的⼆进制⽇志⽂件。
一些配置参数:
max_binlog_size=104857600 ⽤于设置每个 binlog ⽂件的⼤⼩,不建议设置太⼤,⽹络传送起来⽐较麻烦。当 binlog ⽂件达到 max_binlog_size 时,MySQL 会关闭当前⽂件并创建⼀个新的 binlog ⽂件。expire_logs_days = 7 ⽤于设置 binlog ⽂件的⾃动过期时间为 7 天。过期的 binlog ⽂件会被⾃动删除。防⽌⻓时间累积的 binlog ⽂件占⽤过多存储空间,技术派实战项⽬所在的项⽬是丐版服务器,所以这个配置很重要。 binlog-do-db=db_name,指定哪些数据库表的更新应该被记录。 binlog-ignore-db=db_name ,指定忽略哪些数据库表的更新(比如有一些我们不在乎或者实现一致性是没有必要的)。 sync_binlog=0 ,设置每多少次 binlog 写操作会触发⼀次磁盘同步操作。默认值为 0,表示 MySQL 不会主动触发同步操作,⽽是依赖操作系统的磁盘缓存策略。即当执⾏写操作时,数据会先写⼊缓存,当缓存区满了再由操作系统将数据⼀次性刷⼊磁盘(只用我们OS自己的策略)。如果设置为 1,表示每次 binlog 写操作后都会同步到磁盘,虽然可以保证数据能够及时写⼊磁盘,但会降低性能。
注意,这里是把binlog cache刷入binlog磁盘文件内部.
MariaDB [db01]> show variables like '%log_bin%';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| log_bin | OFF |
| log_bin_basename | |
| log_bin_compress | OFF |
| log_bin_compress_min_len | 256 |
| log_bin_index | |
| log_bin_trust_function_creators | OFF |
| sql_log_bin | ON |
+---------------------------------+-------+
7 rows in set (0.002 sec)
有了binlog为什么还要undolog redolog? #
binlog 属于 Server 层,与存储引擎⽆关,⽆法直接操作物理数据⻚。⽽ redo log 和 undo log 是 InnoDB 存储引擎实现 ACID 的基⽯。
1.binlog 关注的是逻辑变更的全局记录.比如记录一条sql语句的变化.
2.redo log ⽤于确保物理变更的持久性,确保事务最终能够刷盘成功.
3.undo log 是逻辑逆向操作⽇志,记录的是旧值,⽅便恢复到事务开始前的状态.
另外⼀种回答⽅式。
binlog 会记录整个 SQL 或⾏变化.
redo log 是为了恢复“已提交但未刷盘”的数据,undo log 是为了撤销未提交的事务.
我们理解一下:
| 日志名称 | 作用层级 | 核心关注点 | 核心目的 | 与其他日志的关系 |
|---|---|---|---|---|
| Binlog (Binary Log) | Server 层 | 逻辑变更(SQL 或行数据) | 主从复制、数据恢复(时间点)。它是一个全局、顺序的日志。 | 先于 Redo Log 准备并提交(遵循两阶段提交)。 |
| Redo Log | InnoDB 存储引擎层 | 物理变更(数据页上的修改) | 保证事务的持久性(Durability),即使宕机也能恢复已提交的事务。 | 保证 Redo Log 写入成功是 Binlog 最终提交的前提。 |
| Undo Log | InnoDB 存储引擎层 | 逻辑逆向操作(记录旧值) | 保证事务的原子性(Atomicity)和一致性(Consistency)(用于回滚)以及 MVCC 的实现。 | Redo Log 也会记录 Undo Log 的修改。 |
您的理解:“其实 redo log 还是给 binlog 服务的”,这个逻辑关系是颠倒的。
Redo Log 和 Binlog 的关系是体现在 MySQL 的“两阶段提交” 机制中:
- 准备阶段 (Prepare): 事务的修改写入 Redo Log,并标记为 Prepare 状态。
- 提交阶段 (Commit): 事务的修改写入 Binlog。
- 最终提交 (Commit): Redo Log 标记为 Commit 状态。
如果只写了 Binlog 而没有完成 Redo Log 的 Commit,那么系统会认为这个事务没有成功。
正确的理解是:
- Redo Log 保证了事务执行的 持久性 (即使宕机,已提交的事务也不丢)。
- Undo Log 保证了事务执行的 原子性 (可以回滚) 和 一致性 (MVCC)。
- Binlog 保证了数据库的 可恢复性 (时间点恢复) 和 高可用性 (主从复制)。
我们来举个例子,以⼀次事务更新为例:
# 开启事务
BEGIN;
# 更新数据
UPDATE users SET age = age + 1 WHERE id = 1;
# 提交事务
COMMIT;
1.事务开始的时候会⽣成 undo log,记录更新前的数据,⽐如原值是 18:
事务开始之前,undolog先记录下来之前的value.
undo log: id=1, age=18
2.修改数据的时候,会将数据写⼊到 redo log。 ⽐如数据⻚ page_id=123 上,id=1 的⽤户被更新为 age=26:
redo log (prepare):
page_id=123, offset=0x40, before=18, after=26
3.等事务提交的时候,redo log 刷盘,binlog 刷盘。 binlog 写完之后,redo log 的状态会变为 commit:
redo log (commit):
page_id=123, offset=0x40, before=18, after=26
binlog 如果是 Statement 格式,会记录⼀条 SQL 语句:
UPDATE users SET age = age + 1 WHERE id = 1;
binlog和redolog具体的区别? #
binlog 记录的是逻辑⽇志,包括原始的 SQL 语句或者⾏数据变化,例如“将 id=2 这⾏数据的 age 字段+1”。redo log 记录物理⽇志,即数据⻚的具体修改,例如“将 page_id=123 上 offset=0x40 的数据从 18 修改为 26”。 binlog 是追加写⼊的,⽂件写满后会新建⽂件继续写⼊,不会覆盖历史⽇志,保存的是全量操作记录;redo log是循环写⼊的,空间是固定的,写满后会覆盖旧的⽇志,仅保存未刷盘的脏⻚⽇志,已持久化的数据会被清除。 另外,为保证两种⽇志的⼀致性,innodb 采⽤了两阶段提交策略,redo log 在事务执⾏过程中持续写⼊,并在事务提交前进⼊ prepare 状态;binlog 在事务提交的最后阶段写⼊,之后 redo log 会被标记为 commit 状态。可以通过回放 binlog 实现数据同步或者恢复到指定时间点;redo log ⽤来确保事务提交后即使系统宕机,数据仍然可以通过重放 redo log 恢复。
为什么要进行2PC的两阶段提交? #
为了保证 redo log 和 binlog 中的数据⼀致性,防⽌主从复制和事务状态不⼀致。
为什么 2PC 能保证 redo log 和 binlog 的强⼀致性?
假如 MySQL 在预写 redo log 之后、写⼊ binlog 之前崩溃。那么 MySQL 重启后 InnoDB 会回滚该事务,因为redo log 不是提交状态。并且由于 binlog 中没有写⼊数据,所以从库也不会有该事务的数据。
假如 MySQL 在写⼊ binlog 之后、redo log 提交之前崩溃。那么 MySQL 重启后 InnoDB 会提交该事务,因为redo log 是完整的 prepare 状态。并且由于 binlog 中有写⼊数据,所以从库也会同步到该事务的数据。
End.