Virtual Memory:MallocLab #
CSAPP中关于虚拟内存的一点简单笔记。
1.物理和虚拟寻址 #
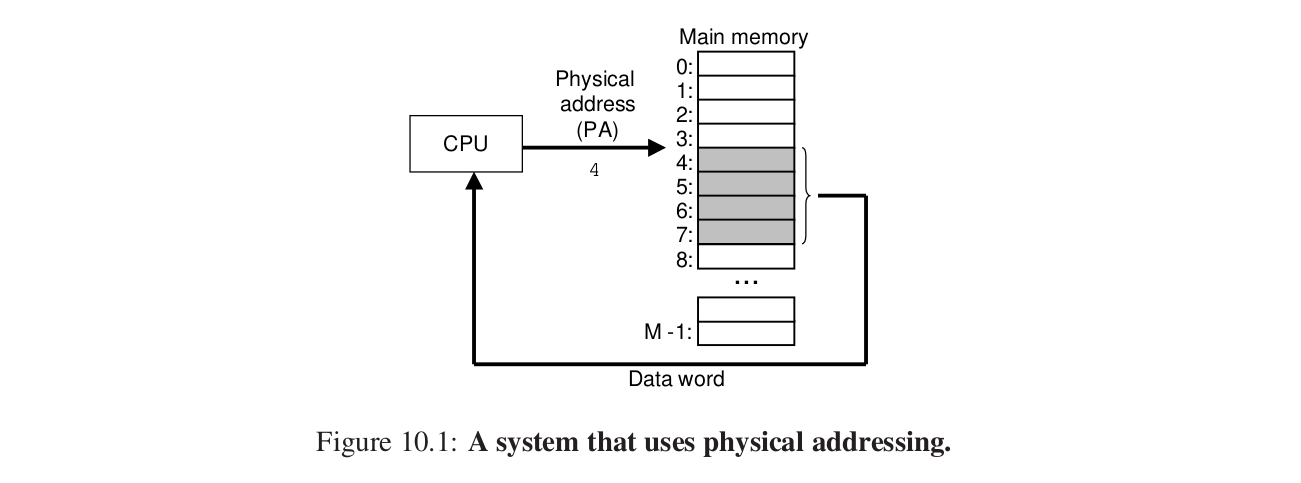
就是CPU直接找地址。
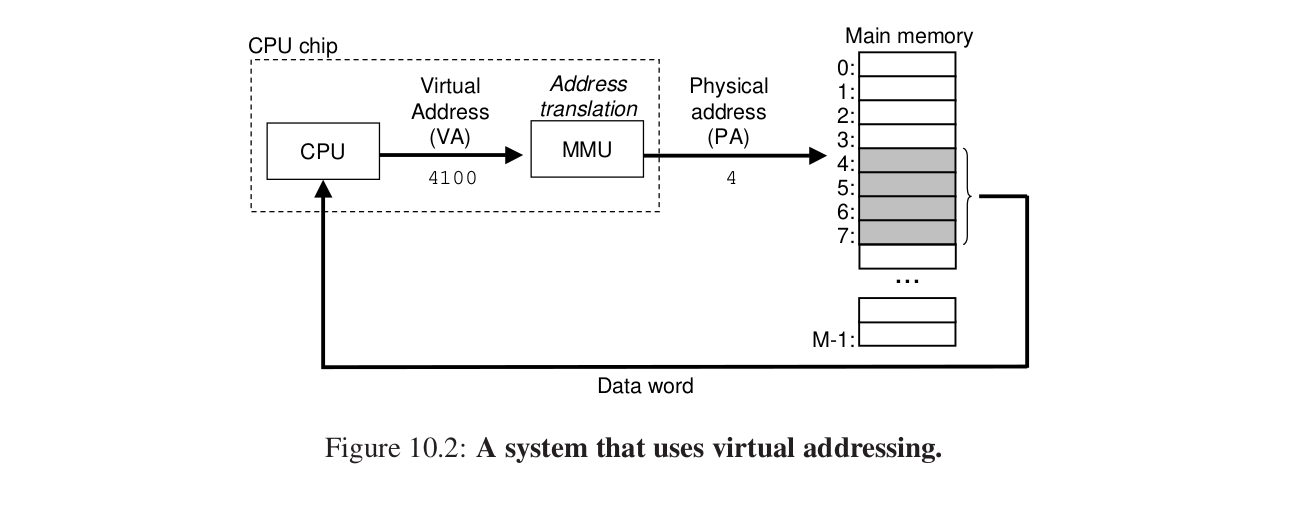
CPU生成虚拟地址,通过MMU翻译。
MMU Memory Management Unit—》利用主存中的查询表来翻译虚拟地址。
2.地址空间 #
Address Space
有物理地址空间和虚拟地址空间。
自然数的有序的连续的有限的一个集合:
$$ {0, 1, 2, … N - 1} $$
3.虚拟内存作为缓存的工具 #
发现还是cache魅力时刻。
概念上虚拟内存被组织为一个存放在磁盘中的字节数组,磁盘上的内容被缓存在主存中。
磁盘上的内容被分割成一块一块的page。
虚拟内存分割成虚拟页VP,物理内存分割成物理页PP。
VP的集合:
1.未分配(磁盘上面的这部分地址还没有被分配)
2.已分配未缓存(分配,但是还没有缓存到物理内存)
3.已分配已缓存
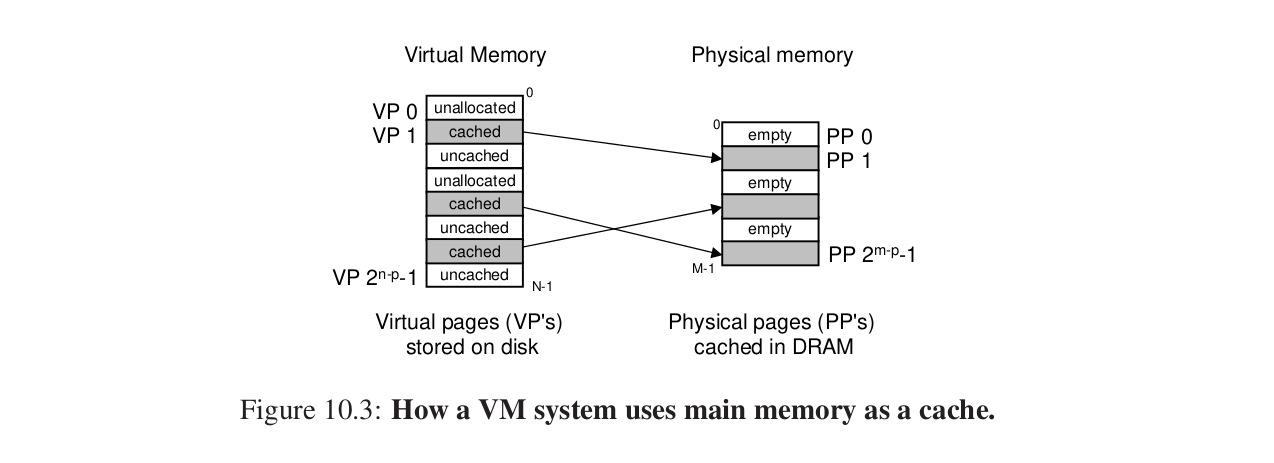
之后我们用SRAM来表示L1 L2 L3高速缓存。
DRAM在主存中缓存虚拟页。
DRAM是全相联缓存,也就是任意的物理页可以包含任意的虚拟页。
1.页表 #
VM要判断某个虚拟页是否存放在DRAM中的某个地方,还要判断放在哪个物理页中,没有就要替换,把磁盘中的虚拟页放在主存中的物理页。
物理内存中放 page table(页表),负责把 虚拟地址—》物理地址。
OS维护页表内容,并且在DRAM和Disk之间传送页。
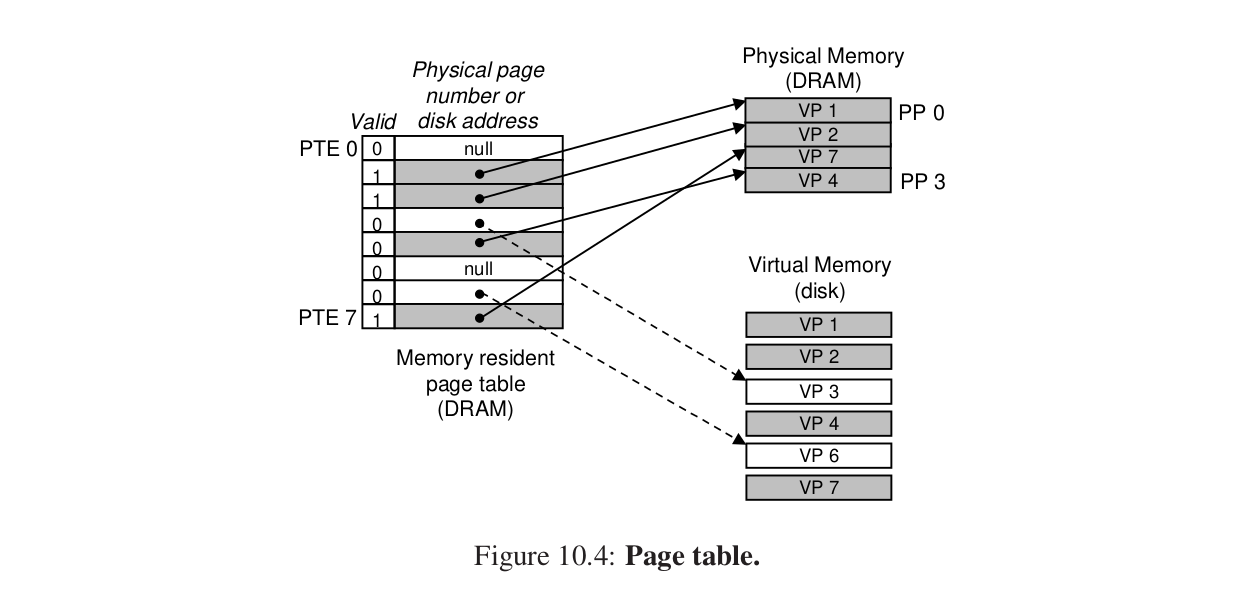
PTE数组。
过程 #
page hit #
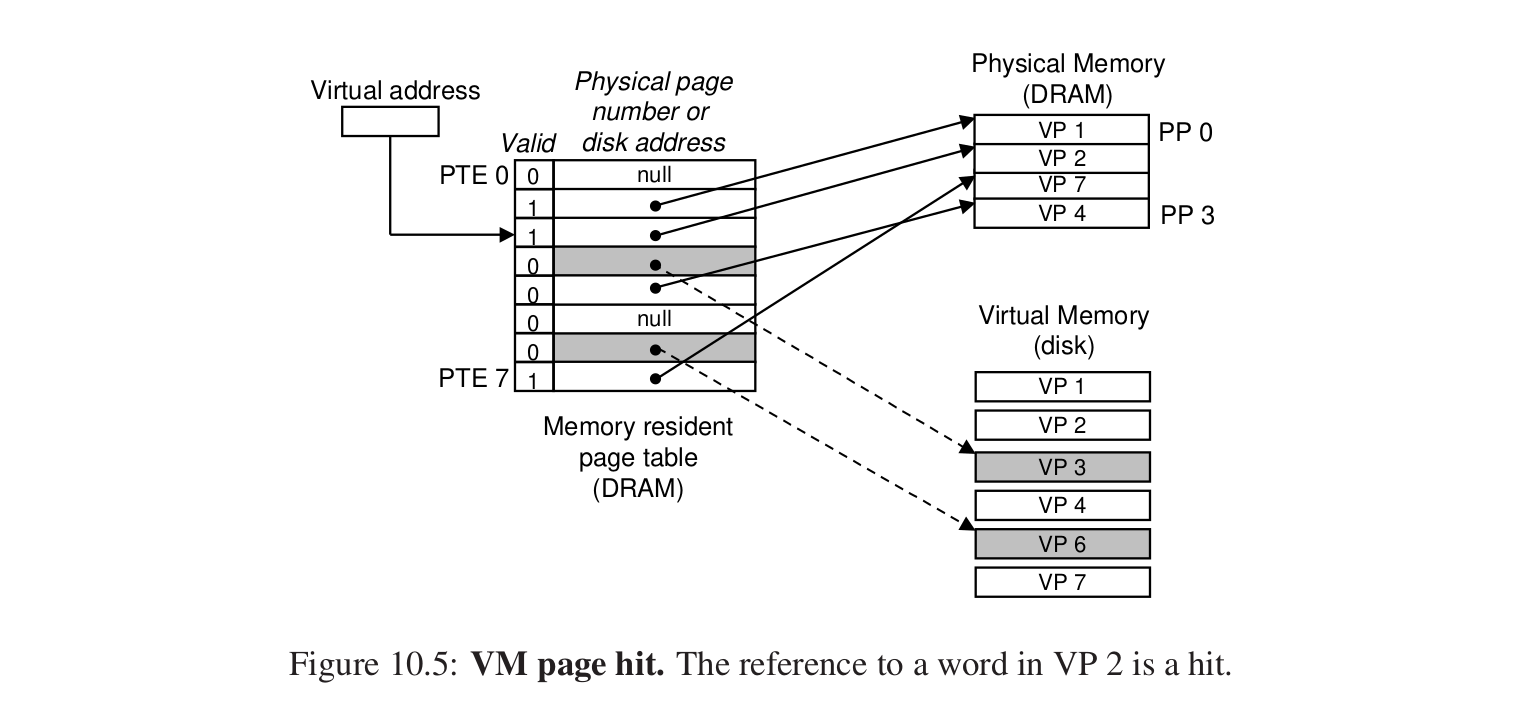
比如读取VP2中的内容,就会发生页命中。
page fault #
就是缺页异常:
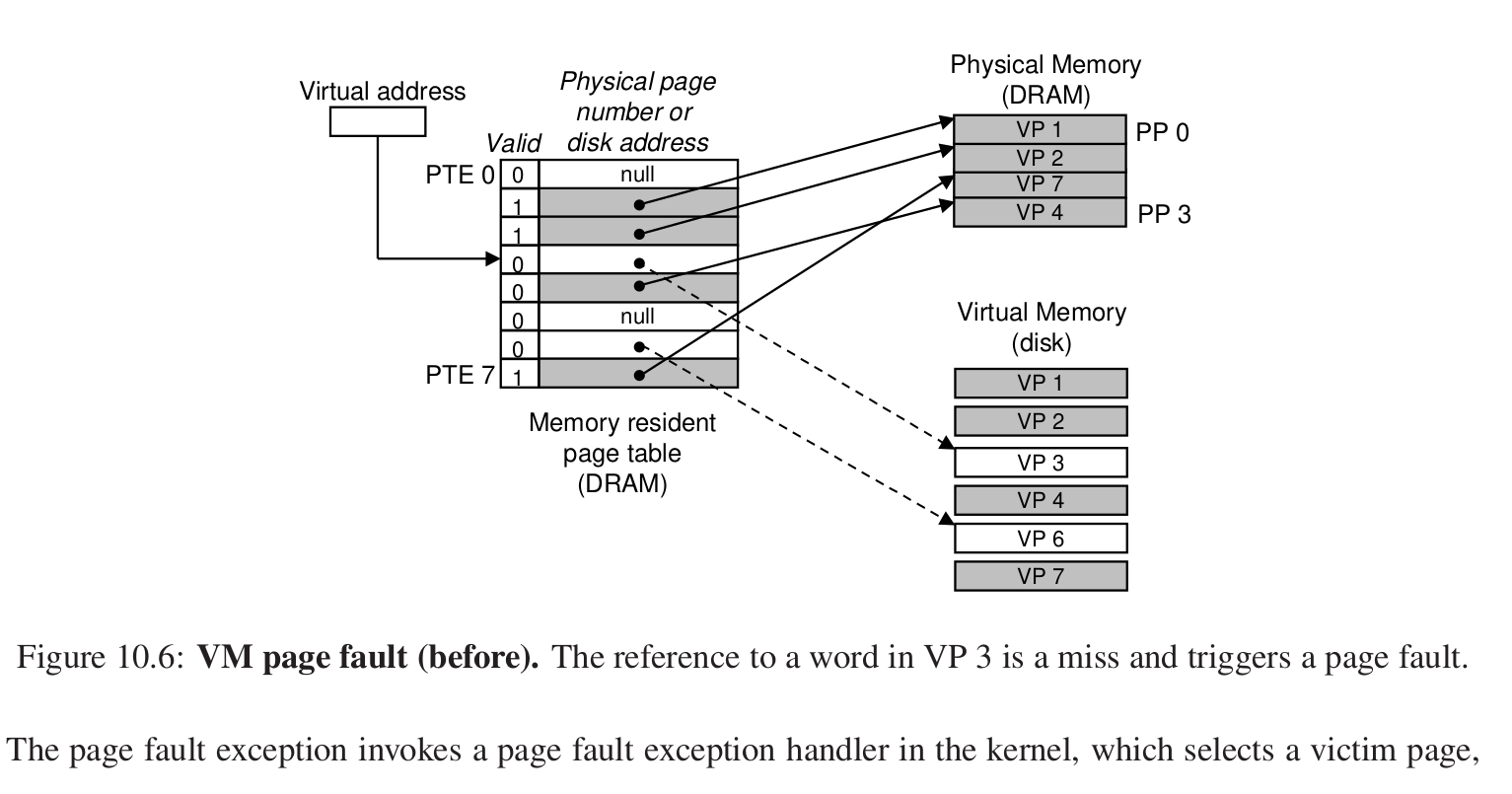
比如在这里,我们想要访问VP3的数据,但是此时valid为0,那么表明没有被加载进DRAM中。
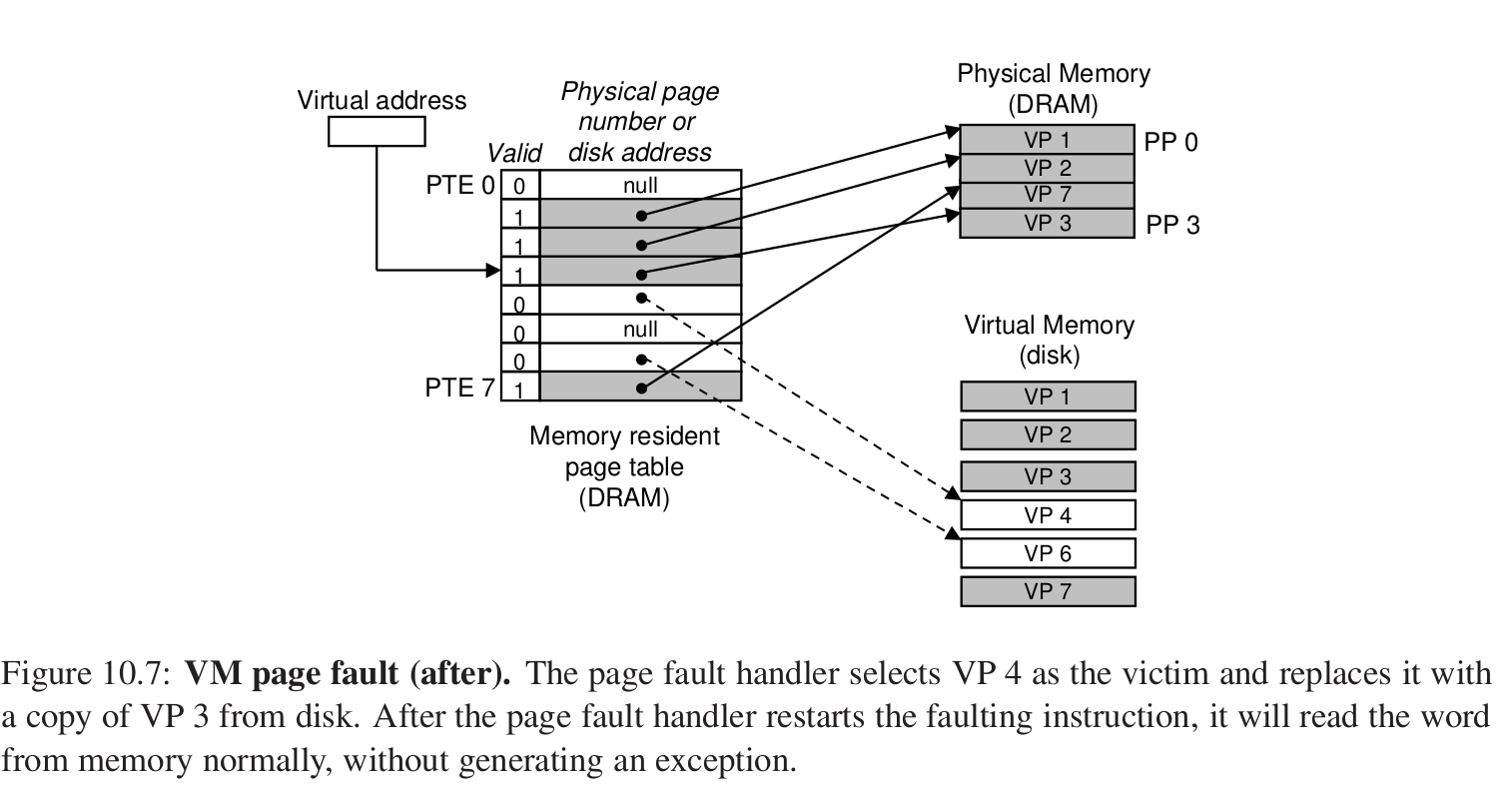
缺页异常会触发缺页异常的处理程序,接着对于某个DRAM中的物理页进行替换,如果页被修改过,还要进行写回,接着把虚拟内存中的Page加载到DRAM中,然后再进行访问。
这就是页面调度,还是cache的思想。
分配页面
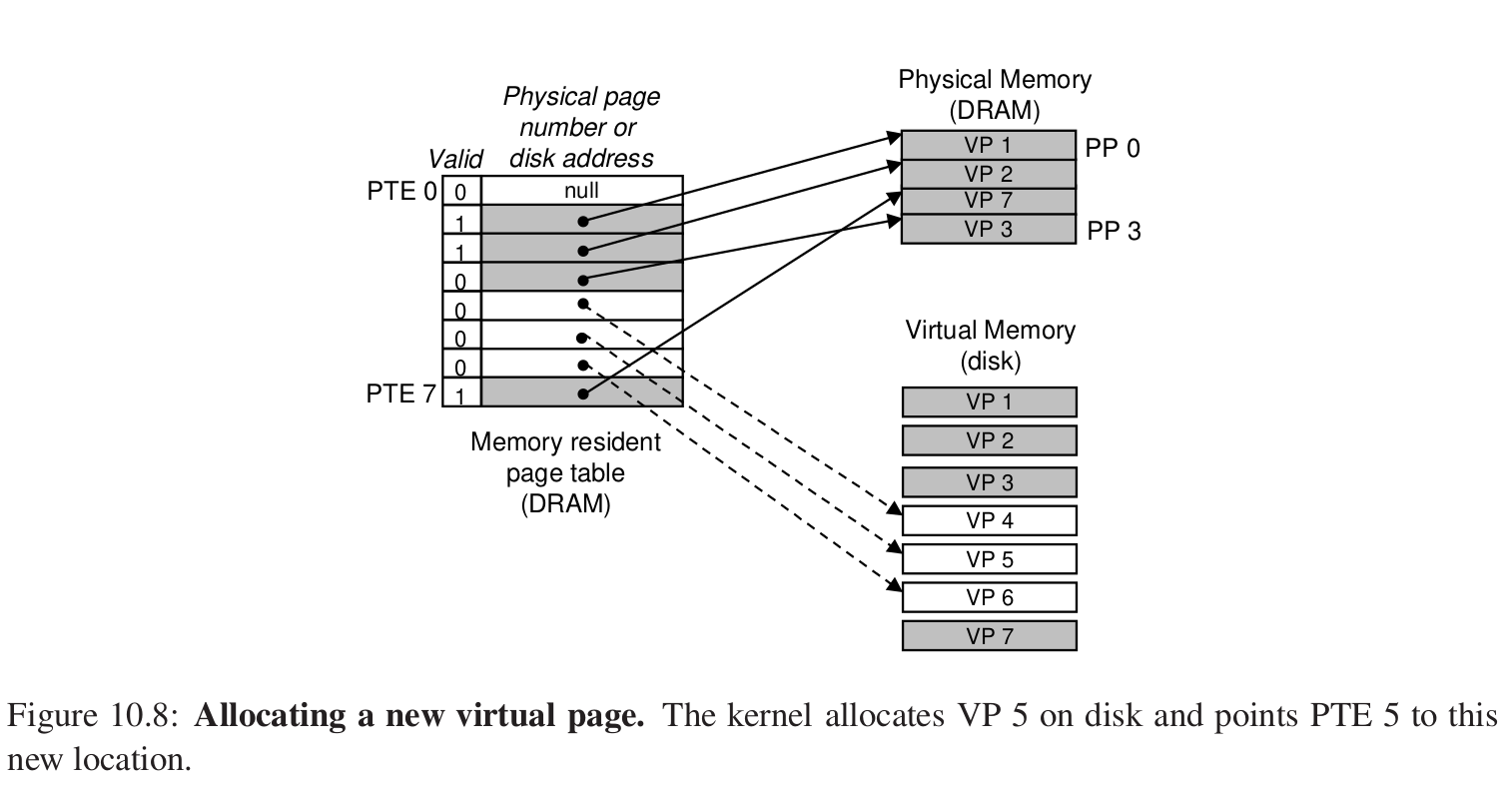
注释。
那么这样的页面调度算法还是要遵从局部性,来提高程序的性能。
4.虚拟内存作为内存管理的工具 #
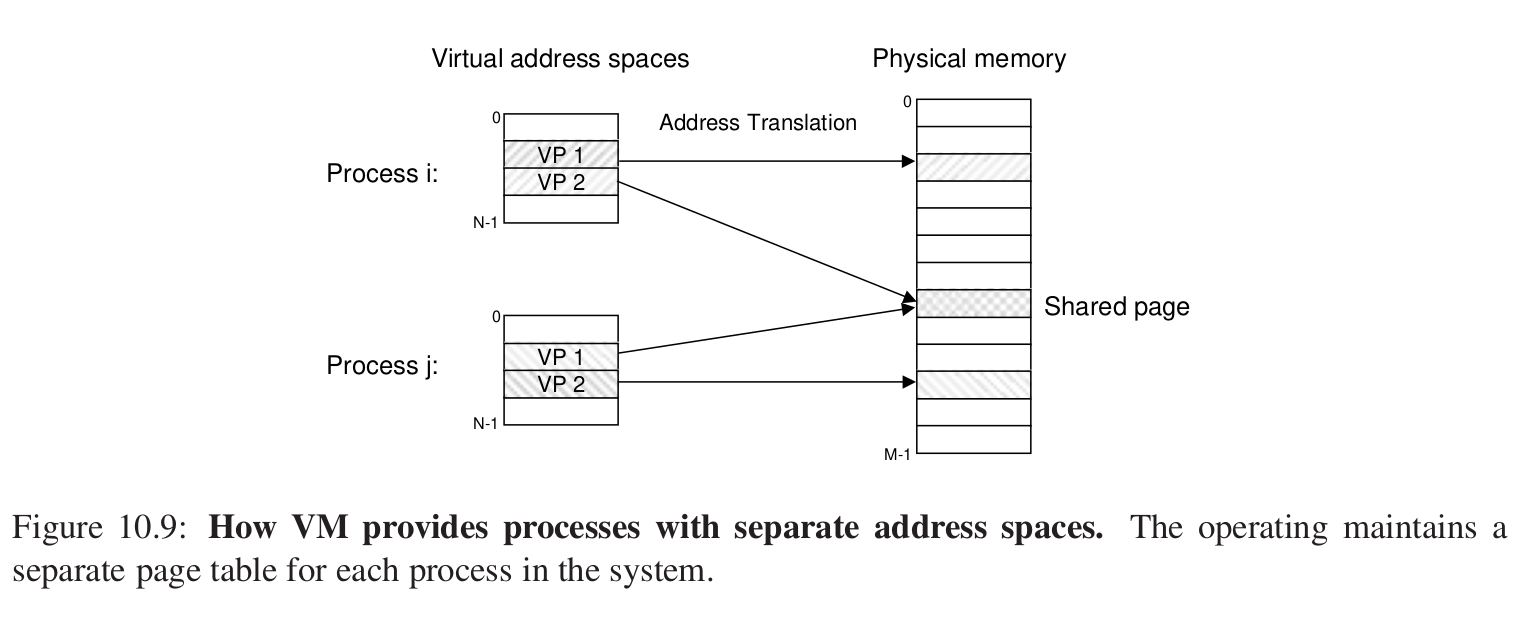
每个进程都有一个独立的页表,也就是独立的虚拟地址空间。
1.简化link的过程,比如代码段总从0x400000开始,可执行文件需要时加载到物理内存中去执行。
2.简化load的过程? mmap 应用程序做内存映射。
3.简化share,比如上面的shared page。
4.简化memory allocation:比如调用malloc函数时,VM分配连续的K个VP,这K个VP映射到分散的K个PP上,这就是为什么堆内存慢。
5.虚拟内存作为内存保护的工具 #
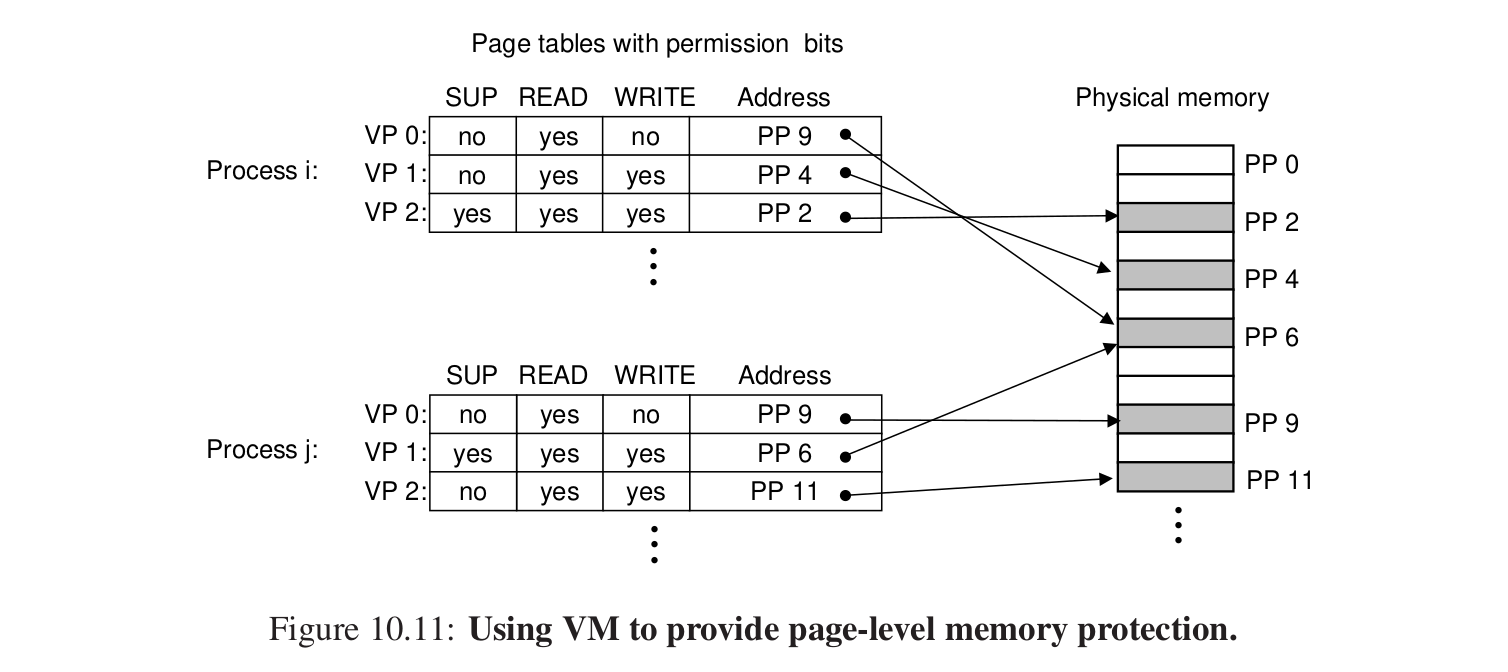
在PTE表中我们可以对于用户的行为来加以限制,违反就会报segmentation fault。
6.*地址翻译 #
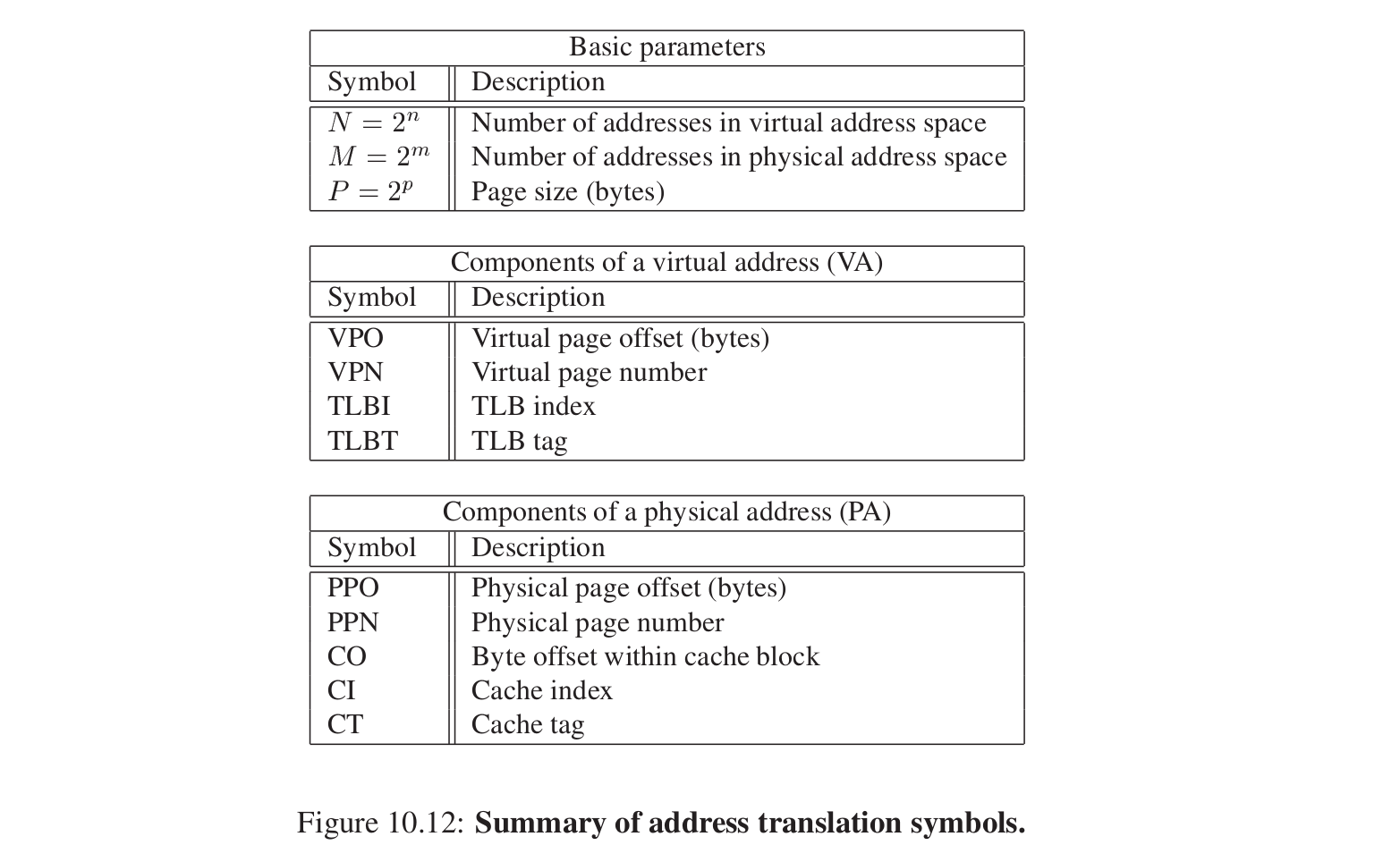
首先记录一些简写。
模拟过程:
虚拟地址是怎么转换的?
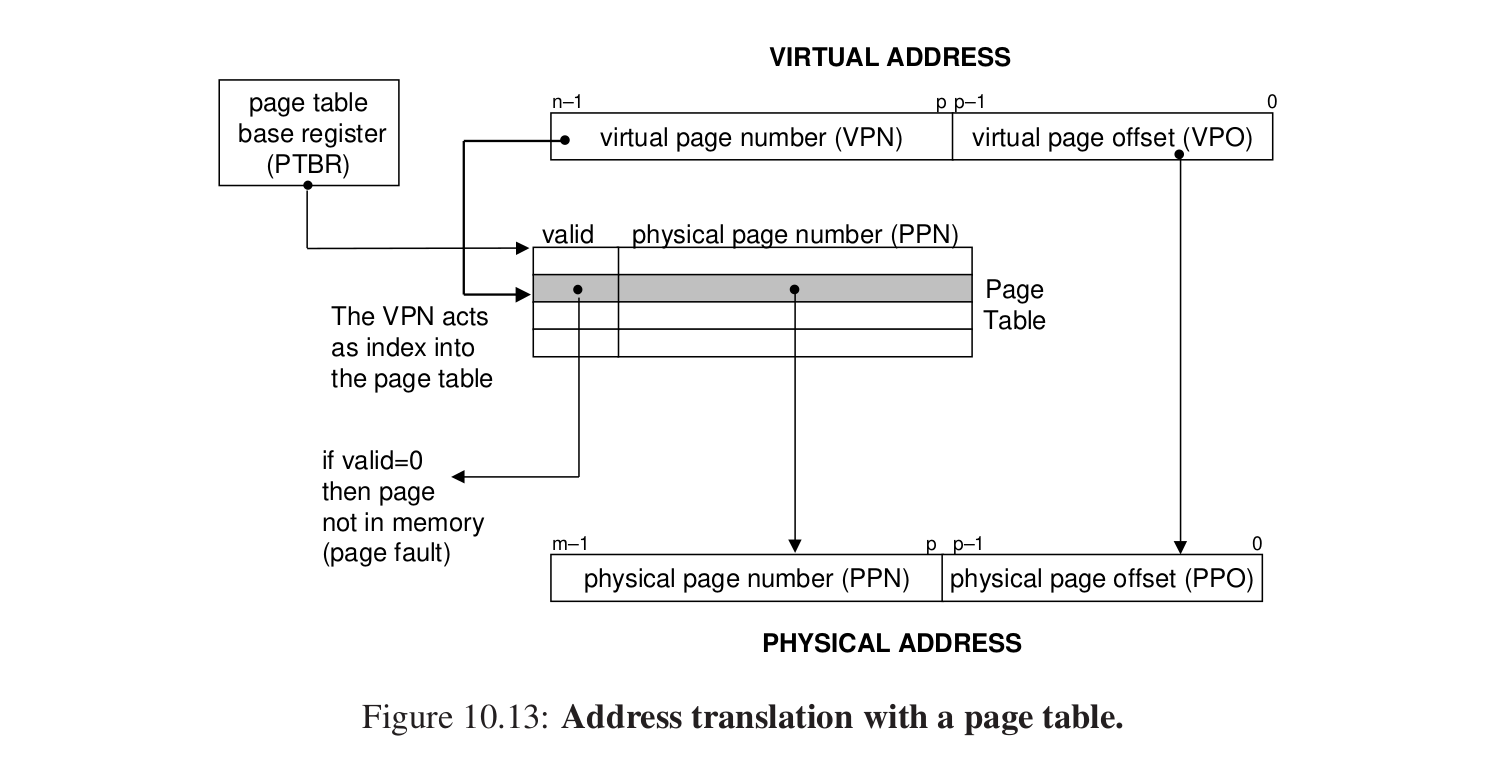
PTBR:页表基址寄存器,指向当前的页表。
拿到一个虚拟地址,低P位是VPO,虚拟页面的偏移量,这个值和PPO相等。
高n - p位是VPN,虚拟页号,在PTE中寻找对应的项,如果valid = 1,那么有效,把后面的位取出来作为PPN,就就是物理页号,和PPO组合,那么这样就组成了物理地址。
page hit的过程是怎样的?
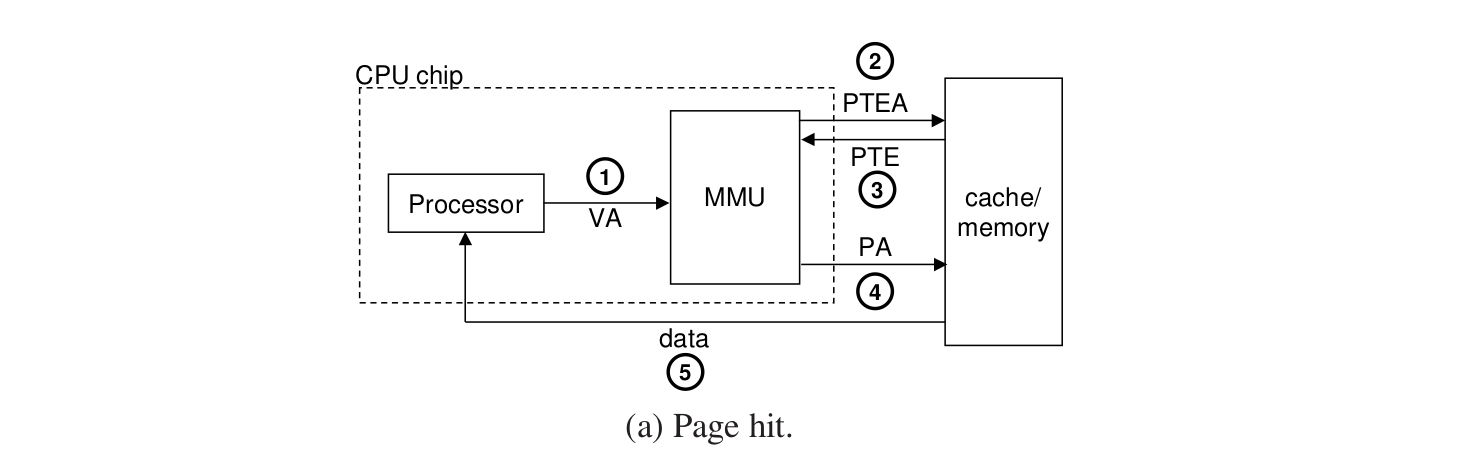
1.CPU把VA给MMU。
2.MMU计算出PTE地址,给主存。
3.主存返回找到的PTE项。
4.MMU用这个PTE构造出来PA,传给主存来请求数据。
5.主存把请求的数据返回给CPU。
如果发生了page fault?
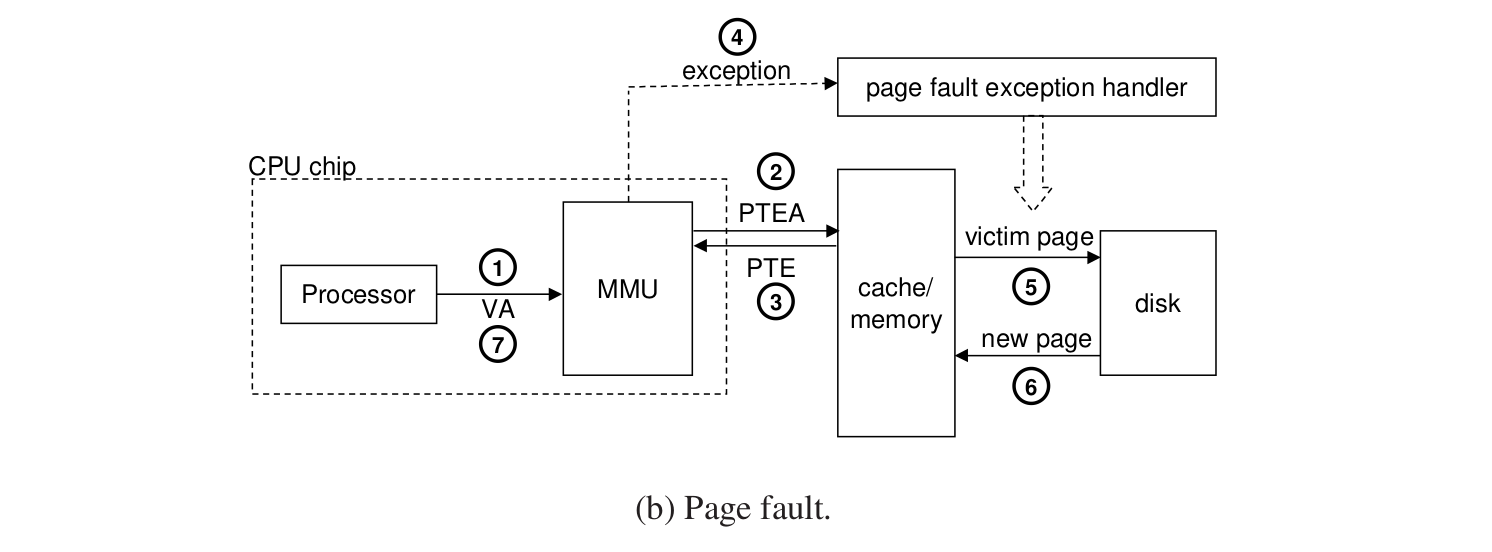
123和原来相同。
4.发生了异常,转到缺页异常处理程序。
5.程序确定逐出的page,如果发生了修改,还要写回到磁盘。
6.从磁盘中加载到内存并且更新PTE。
7.返回到原来的导致缺页异常的处理程序,此时就会命中。
这个过程要硬件配合OS来完成。
1.高速缓存和虚拟内存的结合 #
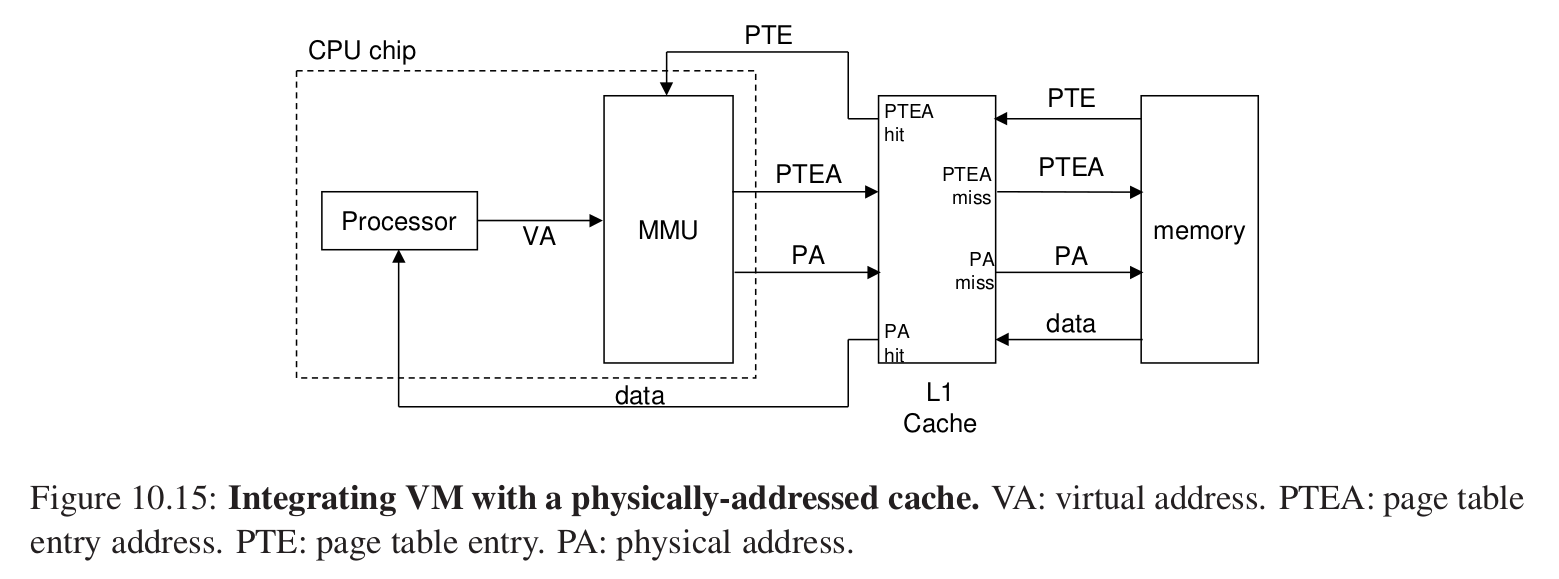
即PTE的页表条目也可以存储在高速缓存中,并没有冲突。
L1寻址在MMU之后,一定使用的是物理地址来寻址,那么取物理地址的过程就和之前的cache是相同的。
地址翻译发生在高速缓存的查找之前。
2.TLB加速地址翻译 #
cache魅力时刻。
MMU中包含了关于PTE的小的缓存:(Translation lookaside buffer)快表。

虚拟地址中怎么访问TLB。
和cache类似,把VPN的分开,低p位作为索引,高n - p - t 位作为标记。
这个过程是类似的:
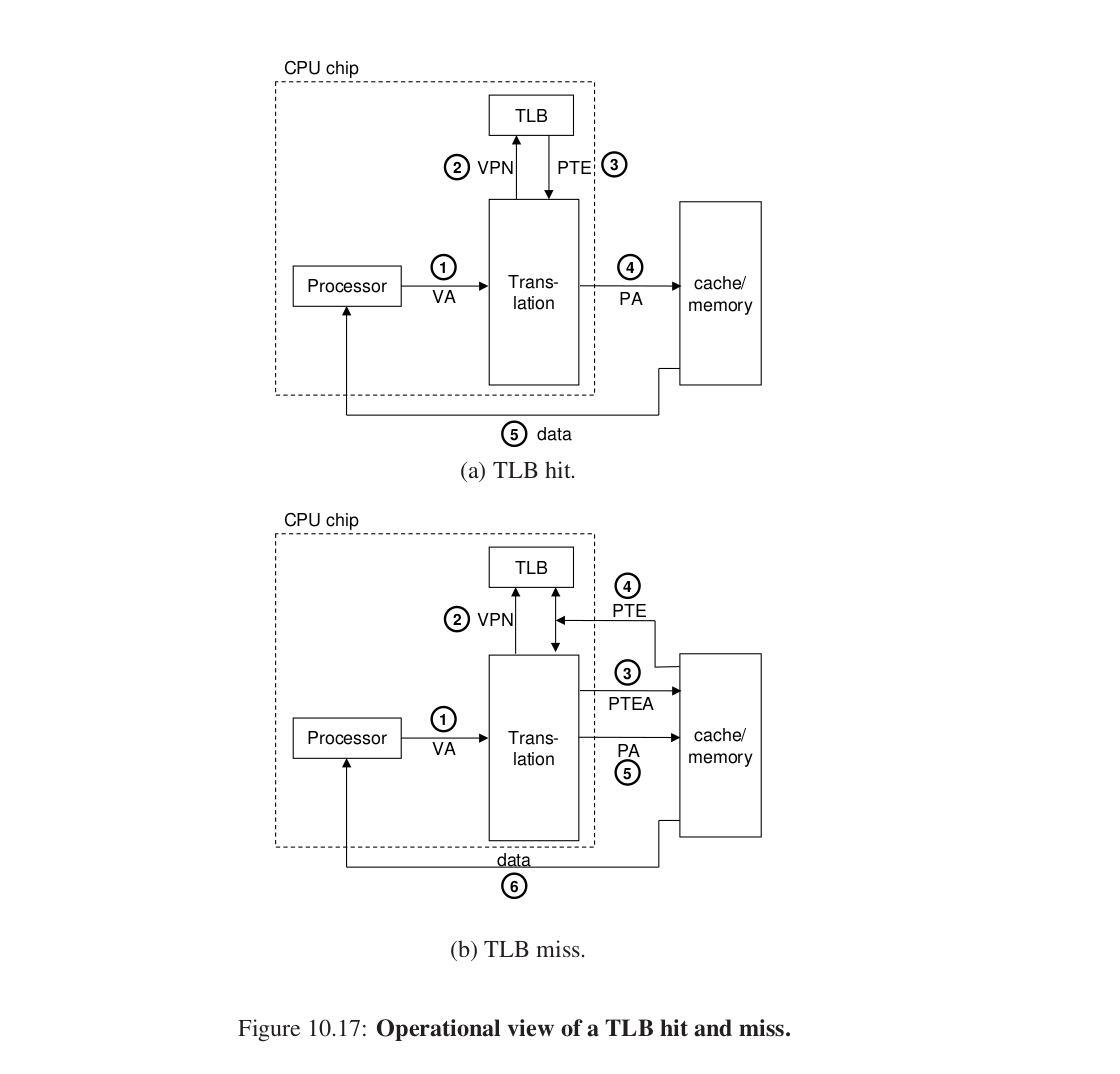
1.VA给MMU。
2.取VPN,在TLB缓存中找相应PTE项。
后面类似。
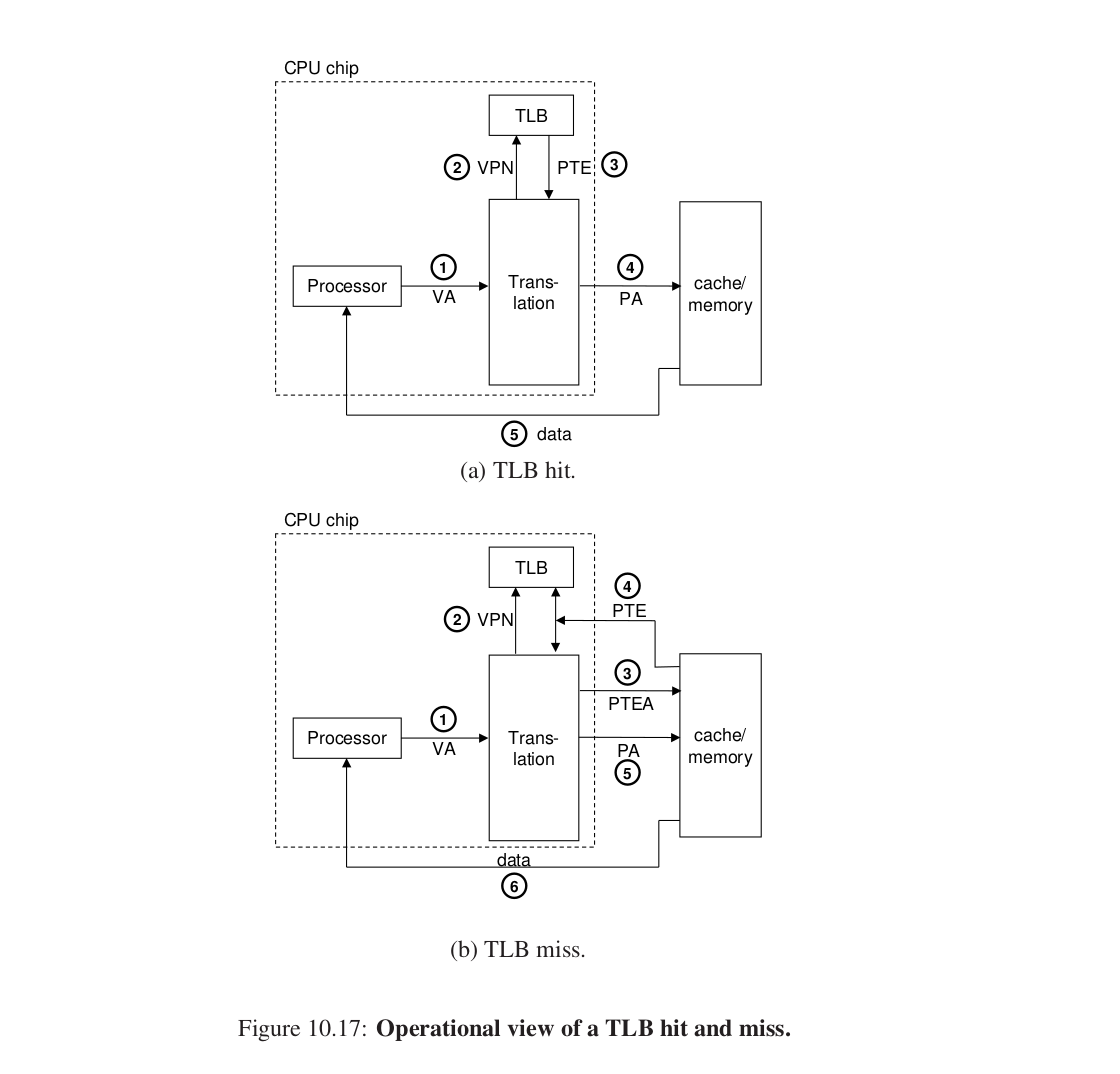
未命中时从内存中获取的PTE还要加载到TLB缓存中。
3.多级页表 #
问题:如果只有一级页表,那么这个页表的所占的内存可能比较大,如果进程很多还各自拥有各自的页表,会产生问题。
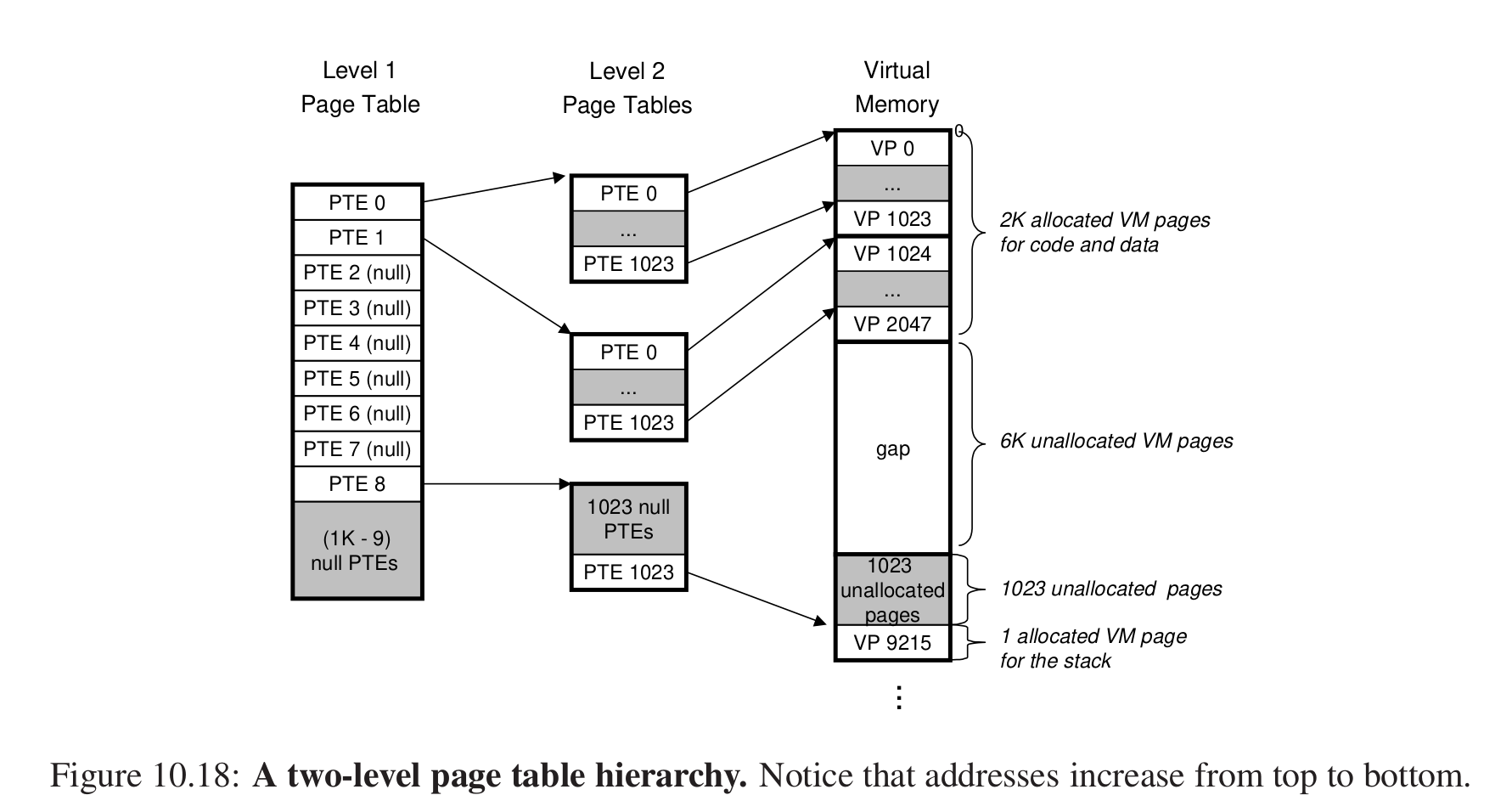
一级页表中的PTE负责虚拟内存中的一片(chunk)。
二级页表中的每个PTE都负责映射一个VP。
为什么能减少内存压力?
1.只有当二级页表中的有某一个部分存在映射的时候,这个二级页表才会存在在内存中,而一般4GB不会都用,这样就能大概做到有多少VP要被映射才会存在多少PTE。使用才会创建。
2.只有一级页表才需要总是存储在主存中。
K级页表怎么翻译?
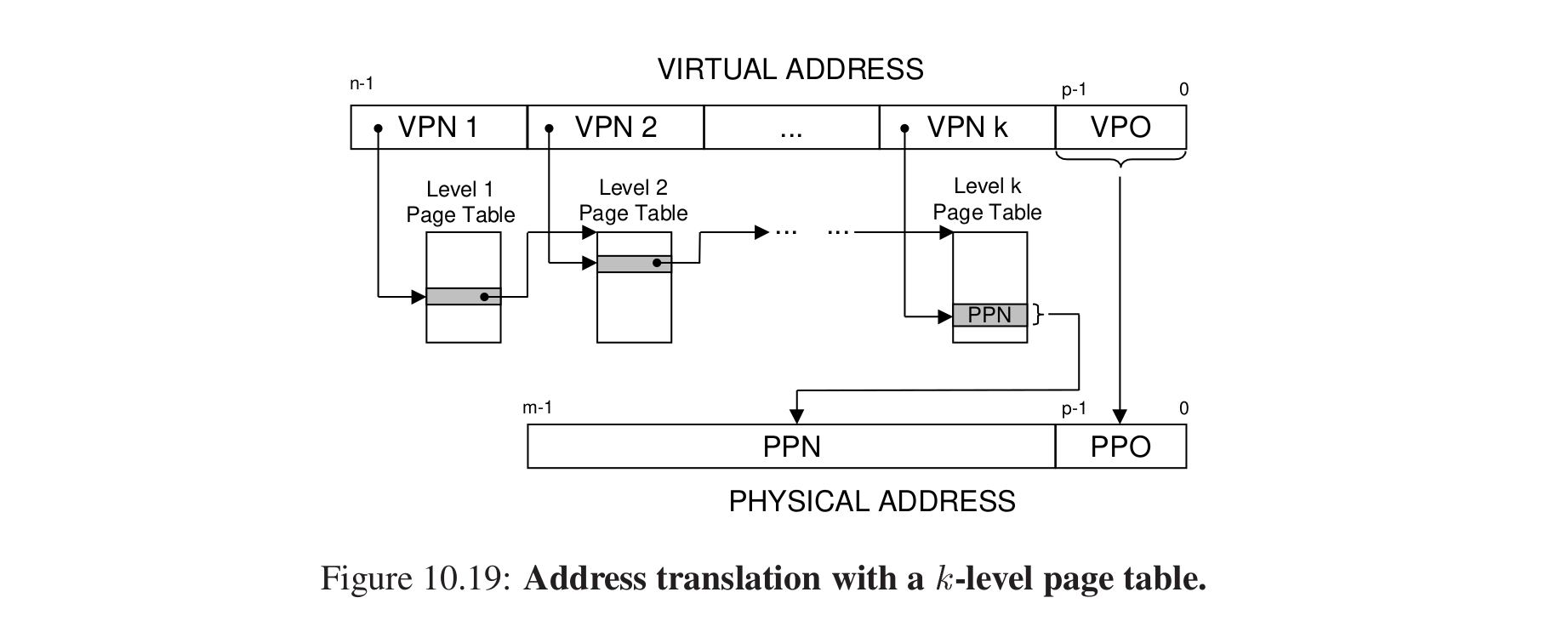
比如对于第j个位置,VPNj是第j个页表的索引,拿到这个页表的索引PTEj,它是下一个页表的基址,这样循环找到最后拿到PPN,和VPO连接得到了物理地址。
“Accessing k PTEs may seem expensive and impractical at first glance. However, the TLB comes to the rescue here by caching PTEs from the page tables at the different levels. In practice, address translation with multi-level page tables is not significantly slower than with single-level page tables.”
也是很天才的设计。
4.手动模拟一下 #
自己看书,比较简单,和之前的关于cache的模拟也是类似的。
7.实际案例 #
比较枯燥,到时候再看。
linux虚拟内存系统 #
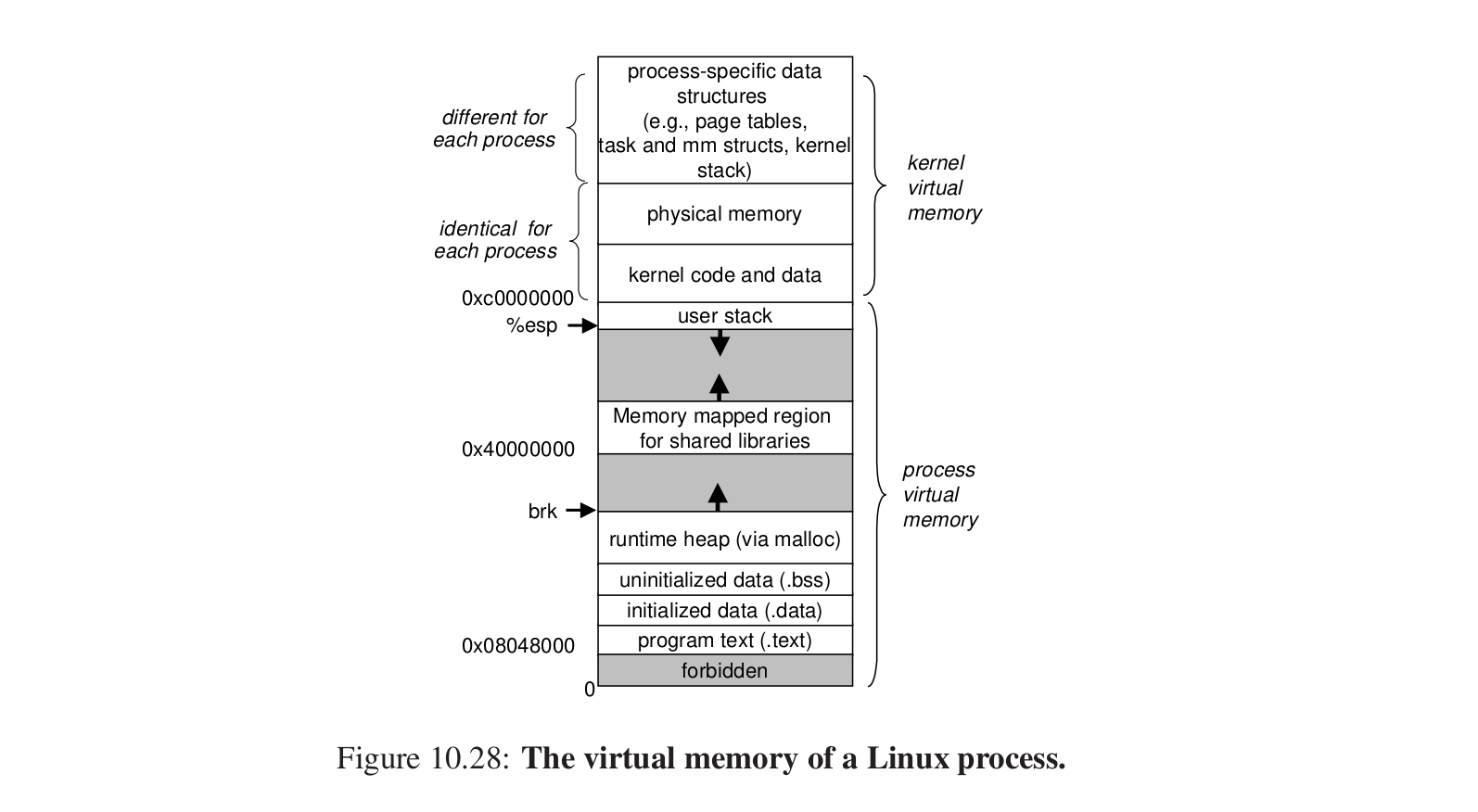
内核虚拟内存和进程虚拟内存。
怎样组织虚拟内存:
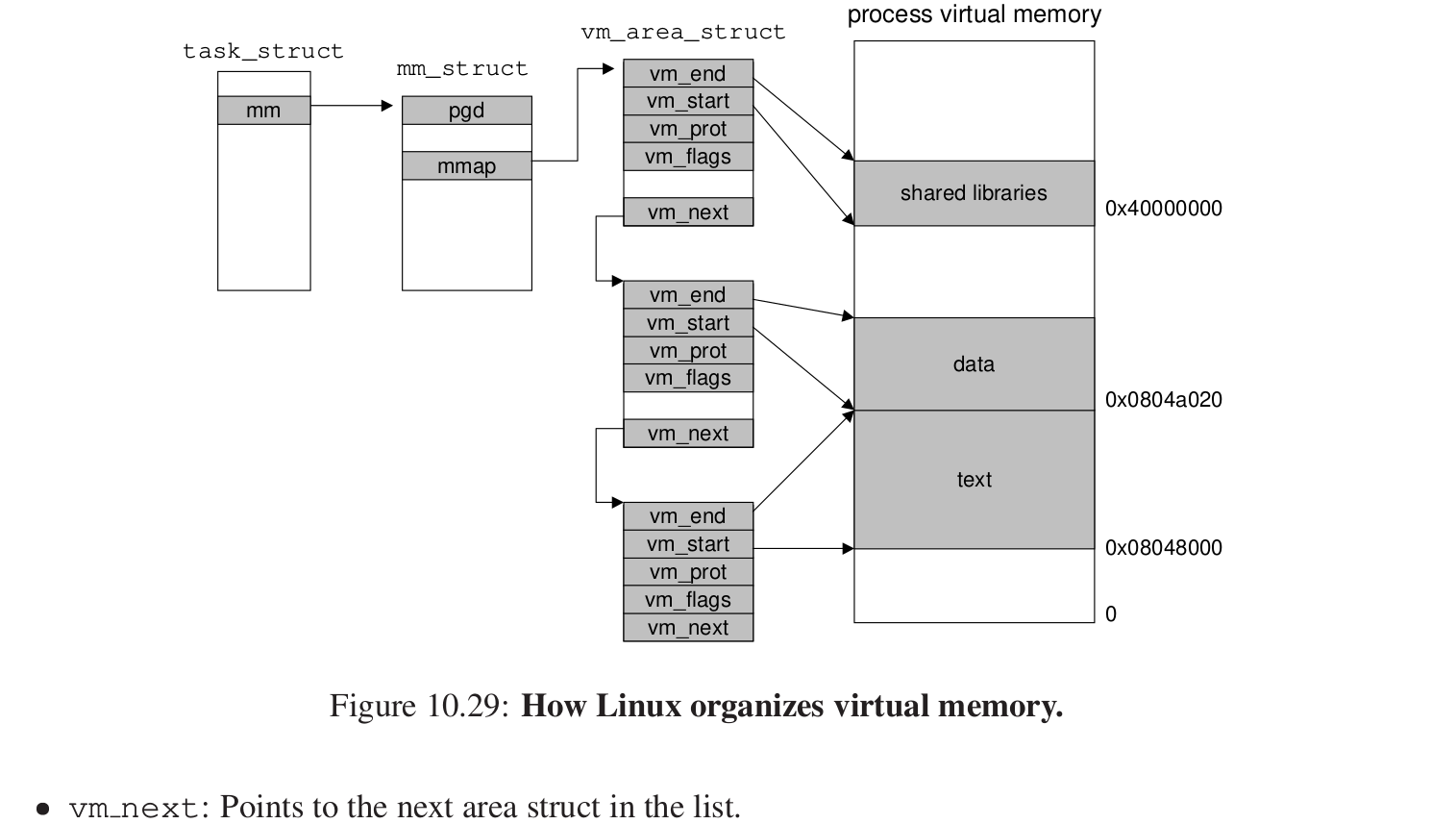
维护一个任务结构,mm_struct维护虚拟内存的当前的一个状态,mmap指向一个链表,链表的每个节点对于虚拟内存中的一些段进行描述。
8.内存映射 #
把一个虚拟内存区域和一个磁盘上的对象关联起来,就是内存的映射:映射到普通文件或者匿名文件。
匿名文件是内核创建的,全部都是二进制0。
在安装linux时,我们会看到swap file,一旦一个虚拟页面被初始化,它就会在这个页面内被换来换去,那么这样的一个空间就会限制进程所能创建的VP的总数。
再看共享对象 #
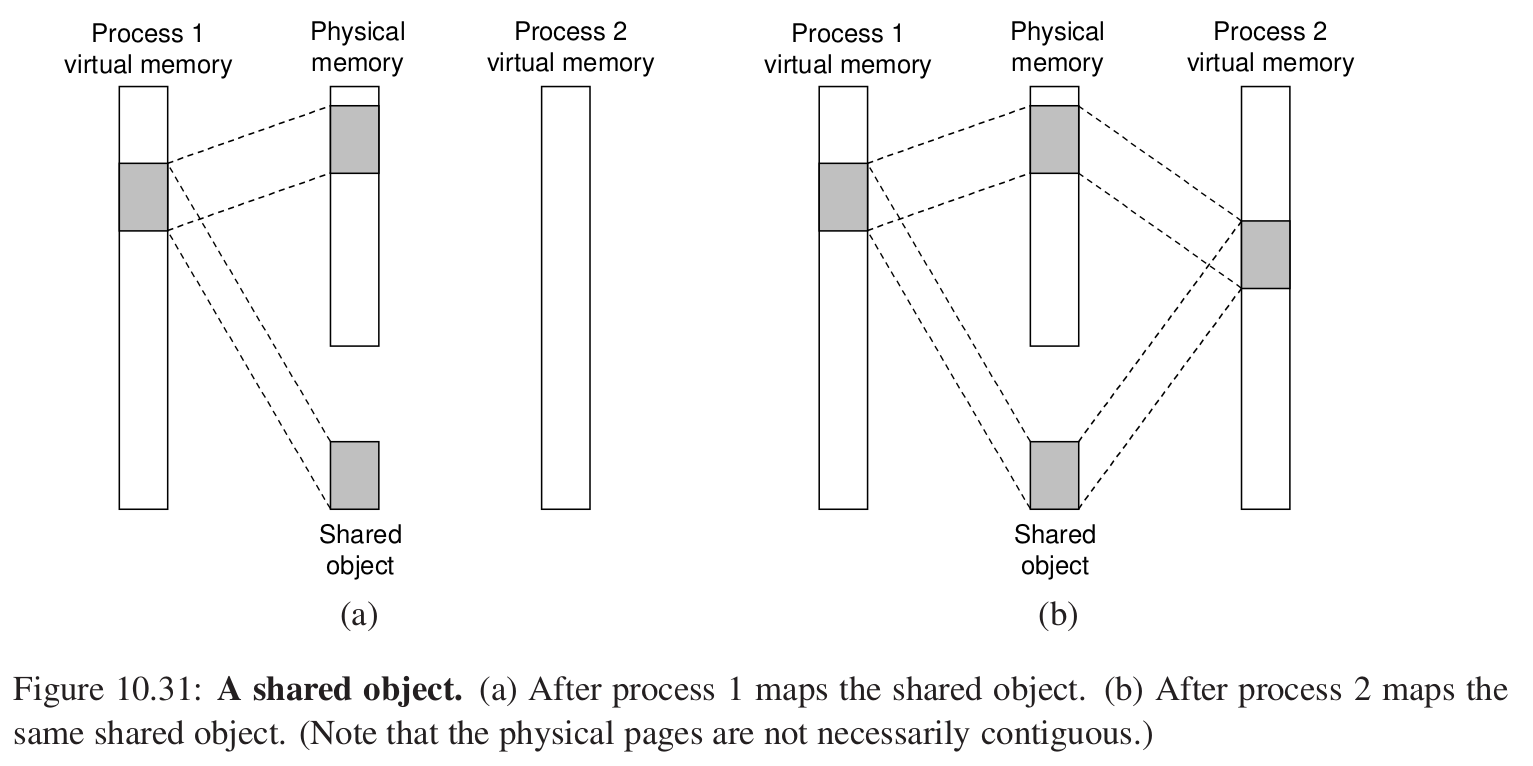
这是一个公共的对象。
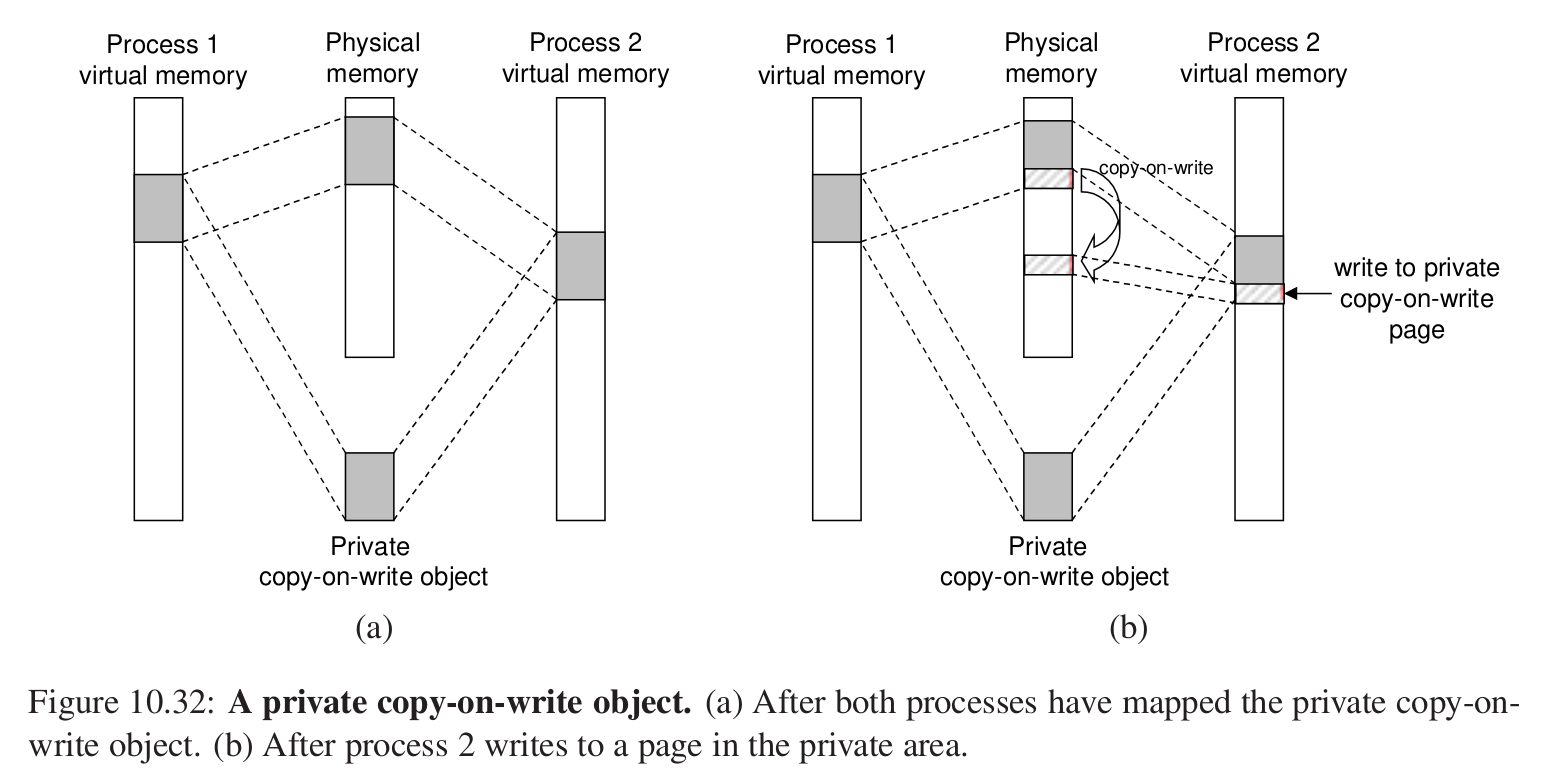
关于这样的私有的对象,采用写时复制的方法,当试图写入的时候,我们才会在物理内存中进行一次复制。
fork函数:当一个进程调用fork的时候,内核为新的进程创建一系列数据结构并且分配PID,返回的时候,两个进程的虚拟内存地址相同,并且设置为写时复制,之后这两个进程中,当有一个试图去写的时候,就会触发写时的复制。
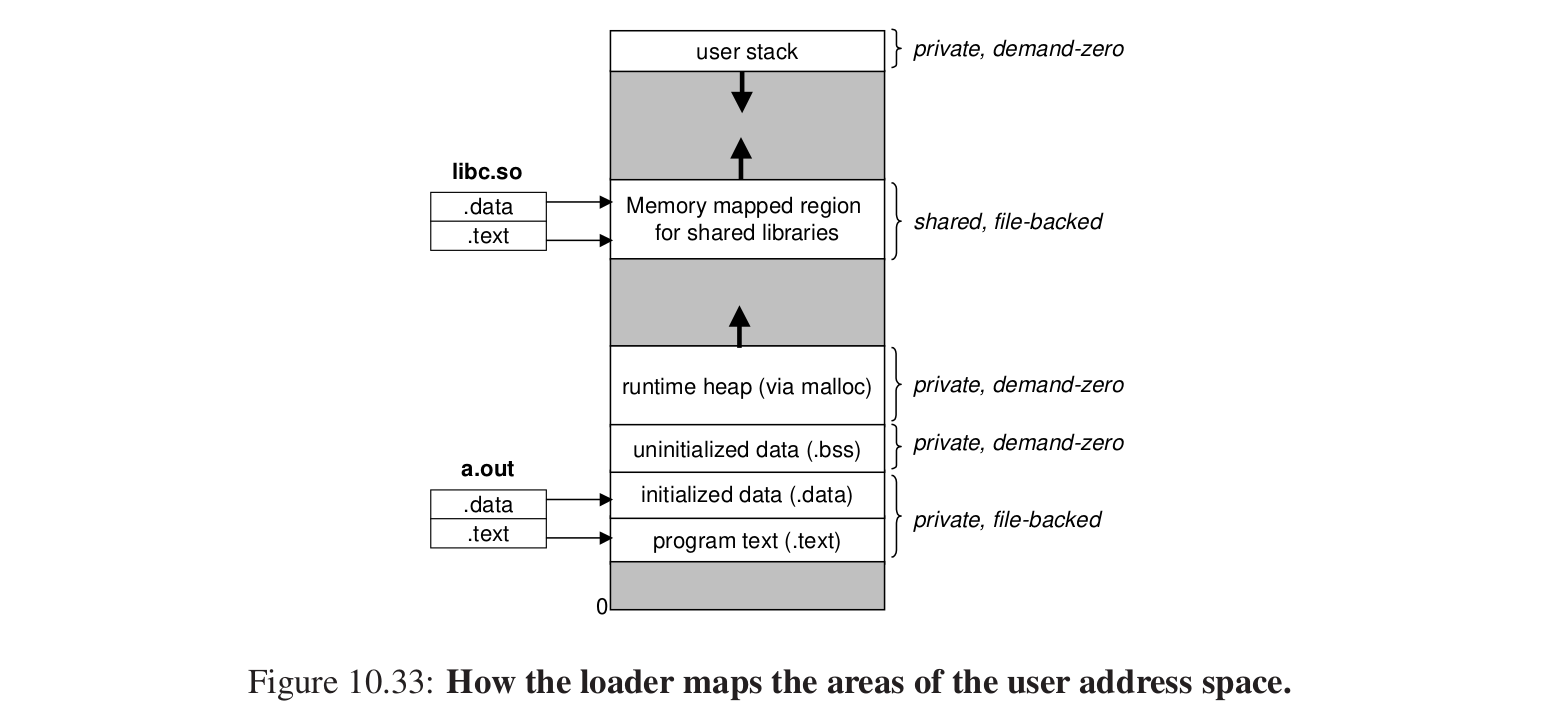
execve函数加载程序:
Malloc Lab #
听说比CacheLab还要更难,让我来挑战一下。
动态内存分配 #
运行时想要额外的虚拟内存,动态内存分配器(dynamic memory allocator)。
进程虚拟内存区域中有一片区域称为堆(heap):
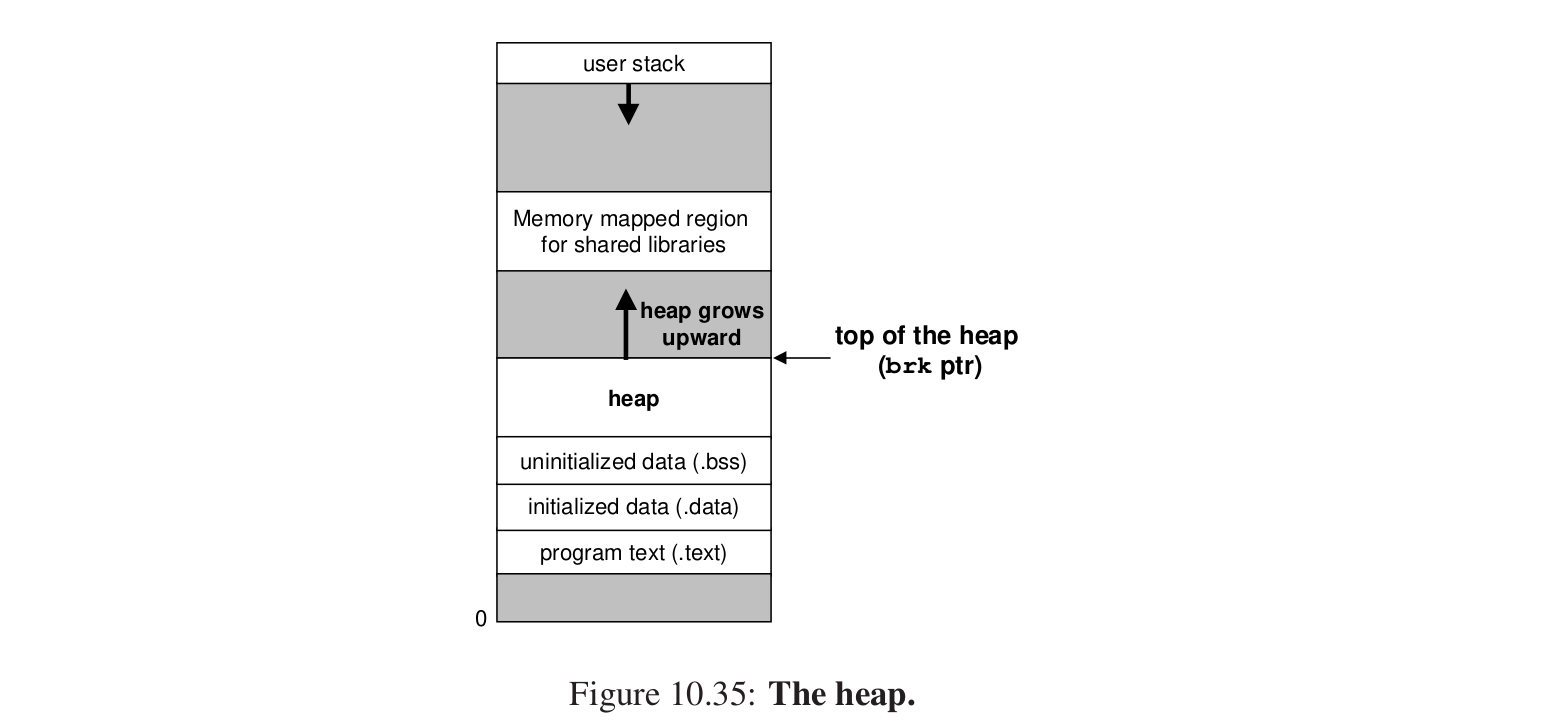
堆顶指针是brk指针。
堆是向上增长的,和用户栈相反。
allocator把heap内存当成一些不同大小的块(block),每个block都是一些连续的虚拟内存的片(chunk),每个块要么空闲,要么已经分配,已经分配的块显式的可以被进程使用,空闲的块可以用来被分配。
分配器:
1.显式分配器:显式的分配和释放,C中的malloc和free函数。
2.隐式分配器:GC,也叫垃圾回收器,自动释放未使用的已分配块(Java中的GC)。
1.malloc和free函数 #
调用:
#include <stdlib.h>
void *malloc(size_t size)
返回至少有size个字节的内存块,分配失败,返回NULL,同时要保证分配的内存以某种标准对齐。
calloc:分配的同时初始化。
realloc:给已经分配内存的块改变大小(本质是重新分配,并且不改变原来的数据)。
分配和释放的过程:
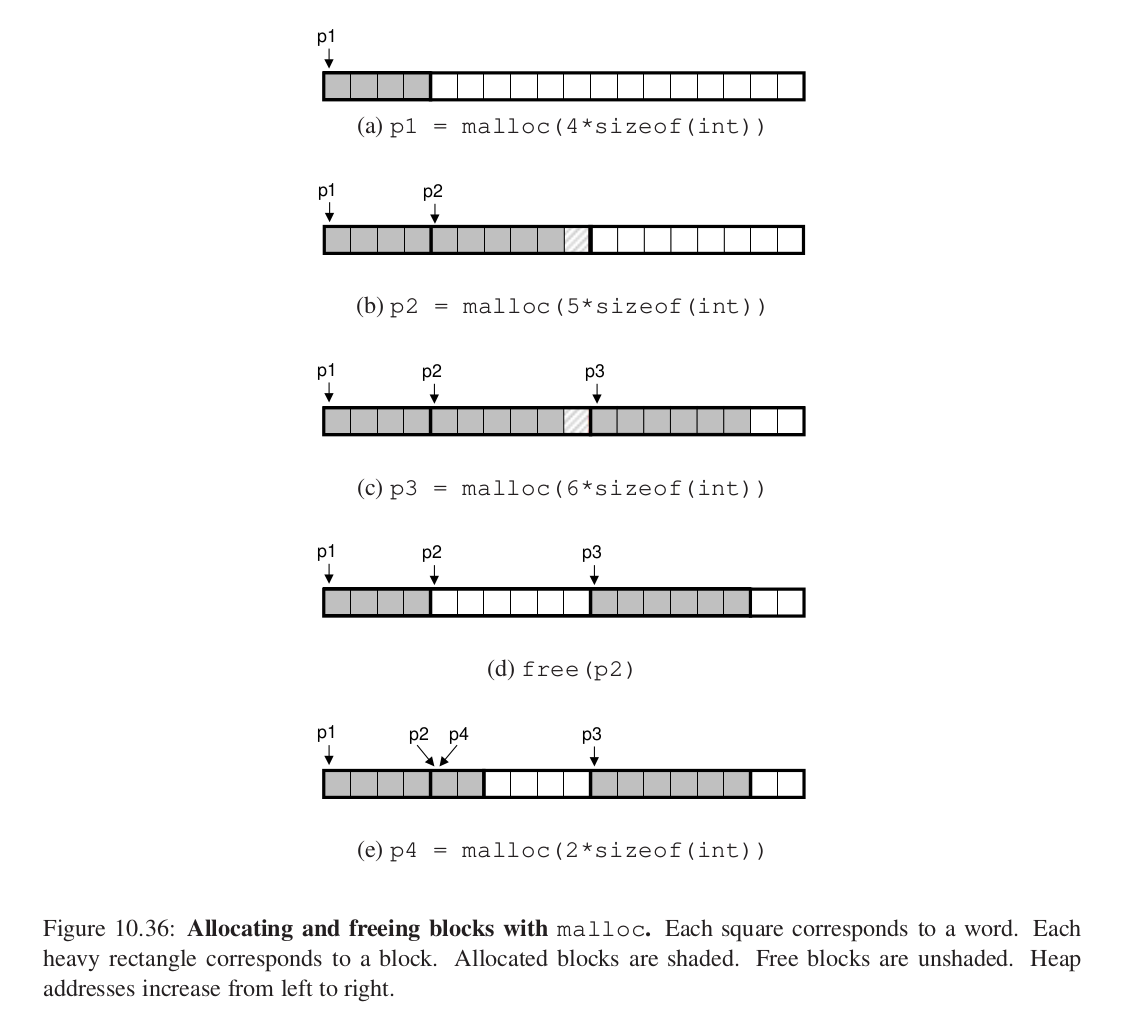
p2的分配就是处于内存的双字对齐的要求。
p2释放之后,程序应当保证不会再使用p2指针(悬挂指针?)。
p4申请内存时,会使用之前的释放的内存。
2.为什么要使用动态内存分配? #
大一学习C程序设计就应该清楚了,很多数据结构的大小运行时才能确定,而我们不想要这样的hard code。
3.分配器的要求和目标 #
1.处理任意请求和释放请求的序列:意思就是随机顺序,不像栈或者队列一样。
2.立即响应请求。
3.只用heap内存。
4.满足对齐要求。
5.不能修改已经分配的块。
性能:
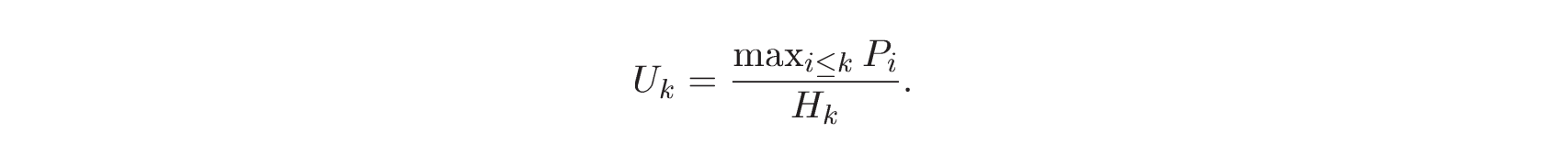
Hk为当前已经分配的堆的大小,Pk是已经分配的聚集有效的载荷之和,我们要让这个Uk峰值利用率最大化。
4.Fragmentation(碎片) #
内部碎片:已经分配的块的大小比有效载荷更大,比如为了对齐的时候造成的,它的大小就是已分配的字节减去有效载荷的字节的大小。
外部碎片:空闲块的数量够,但是没连起来,不能满足请求的块,就是外部碎片。
分配器要试图维持少量的大空闲块,而不是大量的小空闲块。
5.实现的问题 #
空闲块组织:如何记录空闲块?
放置:选择哪里的空闲块来放置新分配的块?
分割:新分配的块放置再某个空闲块之后,我们如何处理这个空闲块?
合并:怎么处理刚刚释放的块?
6.隐式空闲链表 #
分配器的数据结构:

标注一些头部的信息。

注意:最后的终止头部标志着结束。
为什么叫隐含空闲链表?
因为头部的大小隐含连接着两个块,给当前块的地址加上大小就跳转到了下一个块。
简单但是任何操作的开销都要O(n),n是已分配和空闲的块的总数。
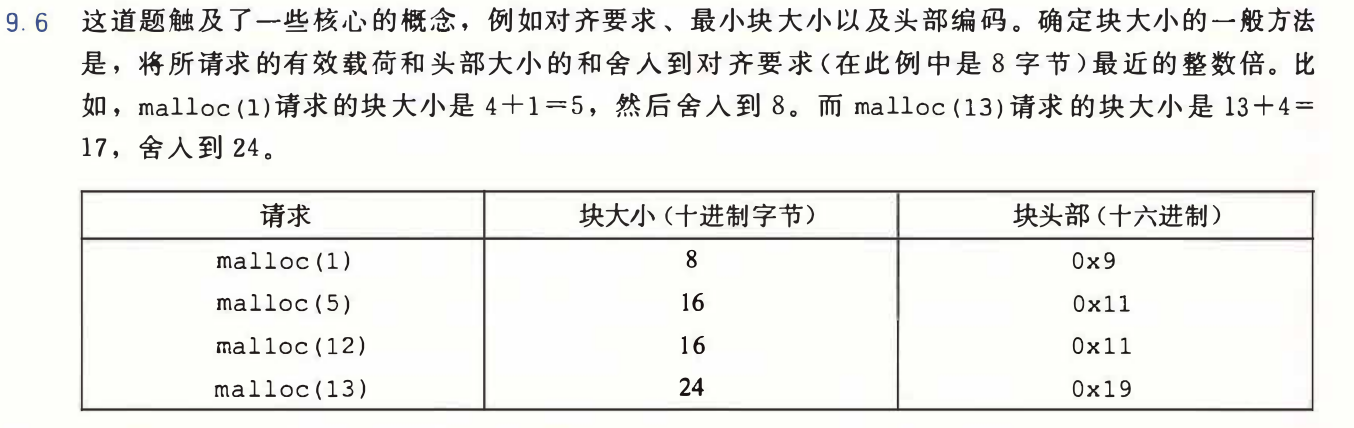
注意9.6这道题目,前面表示大小的29bit不用向后移位的意思,直接表示,和cache那里不一样的地方就在这里。
7.放置已经分配的块 #
我们采用的实现是首次适配。
搜索空闲链表,由放置策略来决定的。
当我们要去找一个能够分配的空闲块时:
首次适配:从头开始直到第一个满足要求。
下一次适配:从上一次查询结束的位置开始寻找。
最佳适配:遍历所有的块,找到能放进去的并且最小的空闲块。
那么上面三者各有利弊,这是很显然的。
8.分割空闲块 #

把上面8个字的空闲块分割成两个4字的,前面分配,后面成为空闲块,也可以都分配,就会造成内部的碎片。
这样也是决策的一种。
9.获取额外的堆内存 #
首先我们尽可能的合并空闲块,接着看合并之后能否生成一个足够大的块容纳请求的内存,如果不能,使用sbrk函数请求额外的堆内存,然后将这块内存插入空闲链表中,然后把要分配的内存进行分配。
10.合并空闲块 #
当释放某个块时,可能会造成两个空闲块并在一起的情况,这就造成了假碎片,那么我们就要进行合并。
那么什么时候合并?
1.立即合并:即释放的时候就对两边进行合并。(但是可能会产生抖动,比如不停的没有意义的合并和分割)
2.延迟合并:只有当分配失败的时候才遍历所有块进行合并。
11.带边界的标记合并 #
考虑我们之前学习过的链表,找链表后面的节点是很简单的,要和后面的块合并,我们只要把当前头部中的块大小加上后面头部的块大小即可,但是前面怎么处理?
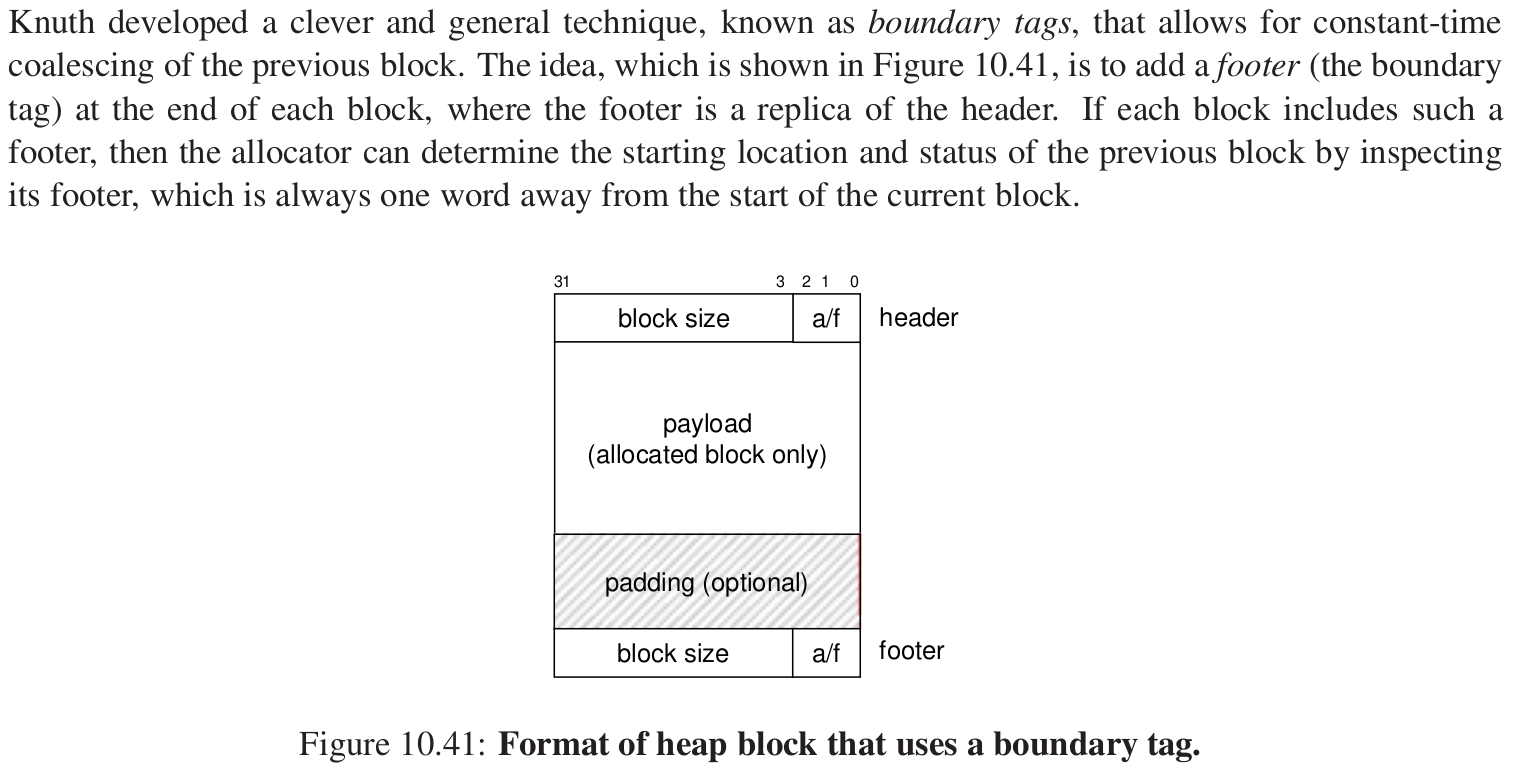
每个块的结尾处加一个footer,它是头部的一个副本,也能表明是否是空闲块,这是否就类似于一种双向链表?
那么释放块的时候就会有以下四种情况:
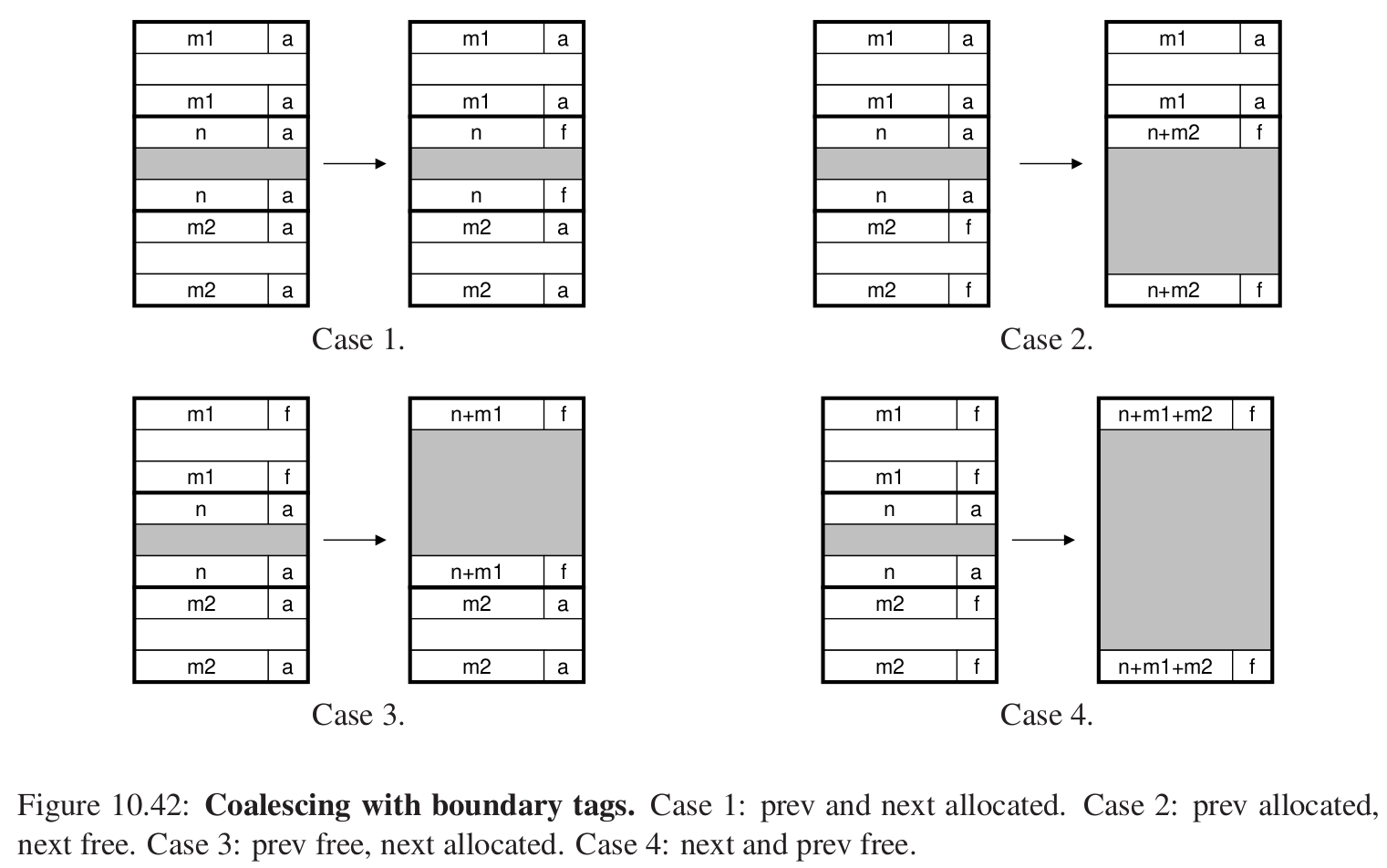
好处很明显,可以看到缺点就是header和footer可能会占用较多的空间。他们都是4bytes,都需要一个字。
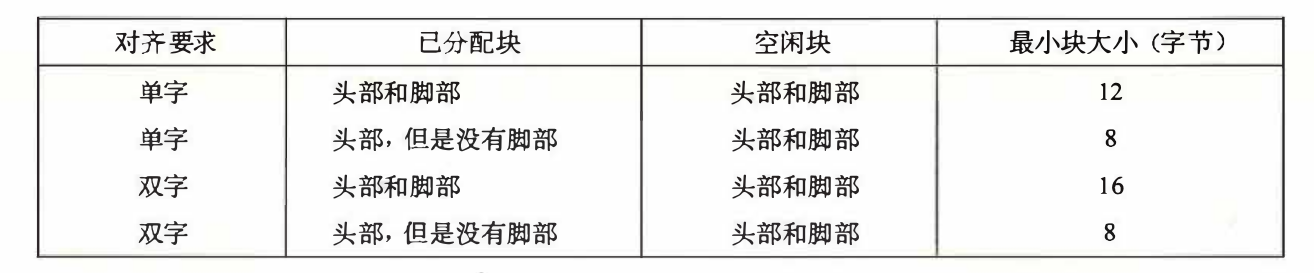
理解这个就没什么太大问题了。
先来开始具体实现,内容之后再补充。
实现要求 #
以下为手册的要求。
内存对齐。在C语言中,任何一种类型都需要对齐访问,例如指向int类型的指针第一个字节指向的位置是4的倍数(因为sizeof(int)=4),同理指向long long类型指针地址是8的倍数。我们这里要求你malloc返回的指针8字节对齐。
malloc与free不得移动、修改已经分配的块,若实现realloc数据点,则不得修改原有数据,任何空间分配不能与已经分配的块重叠。
你的实现需要有:
- 尽可能高的响应速度(吞吐量),即应用发出申请内存的请求到获得内存块首地址的速度尽可能快。
- 尽可能高的空间利用率,因为内存分配器还需要回收内存,所以你需要想办法重复利用不再使用的内存空间,而不是一味地使用全新的空间。
你可以使用的一些工具(function) #
- 一些有关内存拷贝的函数,你可能会在
realloc的实现中使用到,如标准库的memcpy和memmove等。 - 一些数学有关的函数,如 log(需要
math.h头文件)
driver中给出的一些允许用来控制堆空间的函数,以下这些你大概率会使用到:
void *mem_sbrk(int incr):把堆的堆顶指针扩展incr个字节。
void *mem_heap_lo(void):返回当前堆内最低可以访问的字节的地址。
void *mem_heap_hi(void):返回当前堆内最高可以访问的字节的地址。
size_t mem_heapsize(void):返回当前堆的大小。
size_t mem_pagesize(void):返回页的大小(一般来讲是4KB,即字节)。
注意事项: #
由于空间连续,且新申请到的内存是空闲块,所以需要检查一下新申请的块前面是否是空闲块,如果是的话,你需要把它们合并成一个大块。
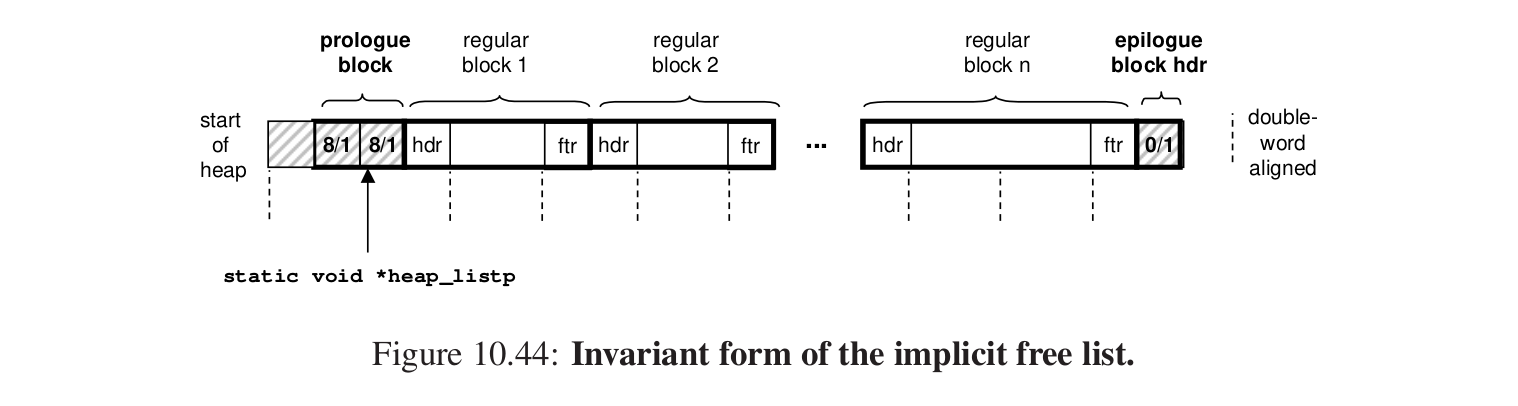
隐式空闲链表会使用序言块和结尾块,开始的四字节空数据用于对齐,后面的8字节跟一个序言块,前四个字节是header,后四个字节是footer(并且是已经分配的),我们的指针指向footer,这是一个已经被分配的块并且始终不会被释放,可以跳转到下一个块。
最后放一个结尾块。4bytes已经分配但是大小为0,这样的块就表明已经到达了堆内存的尾部。
通过朴素的隐式链表和简单的首次匹配,我们拿到了70分,接下来我们来进一步优化。
优化: #
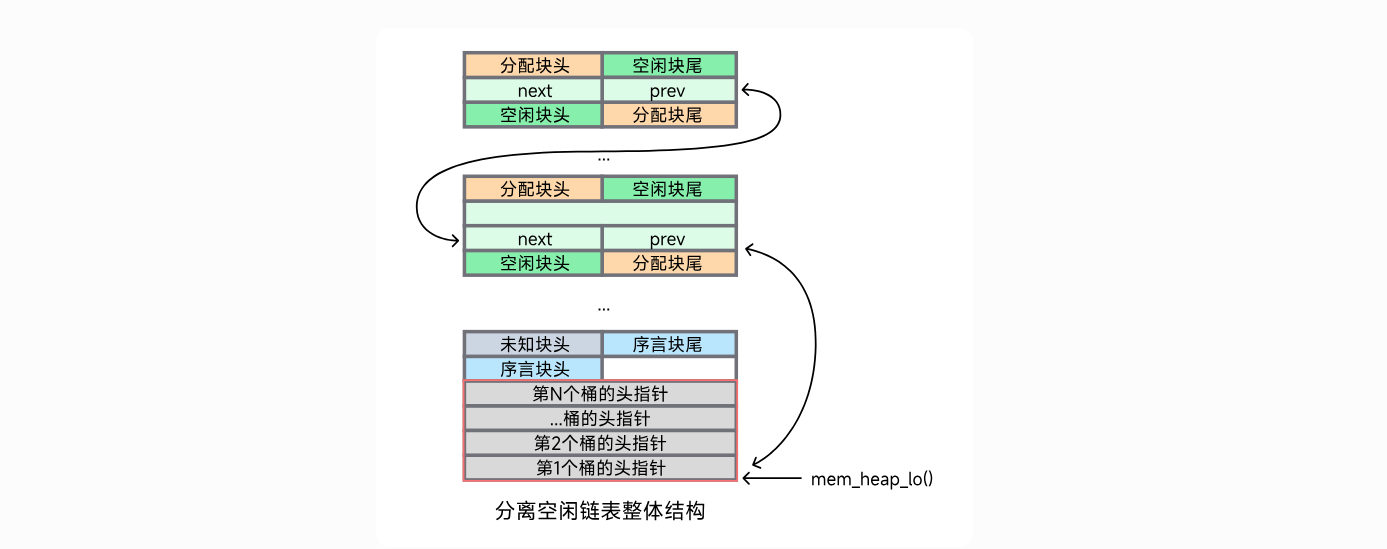
分离空闲链表 #
思想就是把一类大小相同的空闲块放在一起,维护一系列指针,每个指针指向各个大小的类的块。
- 桶(bucket):桶代表一类大小的空闲链表,其头指针存储在堆底。
- 分离空闲链表(free_lists):所有桶的头指针构成的指针数组,其存储在堆底。
图来自于https://arthals.ink/blog/malloc-lab#%E5%9D%97%E7%9A%84%E7%B2%BE%E7%BB%86%E7%BB%93%E6%9E%84

怎么存放在堆底部?那么init的时候是不是要发生变化?
涉及空闲链表指针的操作时,就去加减mem_heap_lo(),来处理。
每个都是64bit。
块的更精细的结构 #
优化,我们减少元数据的信息。
- 对于空闲块,同时存储头部和脚部,元数据信息大小为双字。
- 对于分配块,只存储头部,元数据信息大小为单字。
对于分配块,如果有申请奇数个字的话,可以避免一个字的内存碎片。
空闲块存放可以使前后块迅速获得其信息。
那么两类块的结构如下:
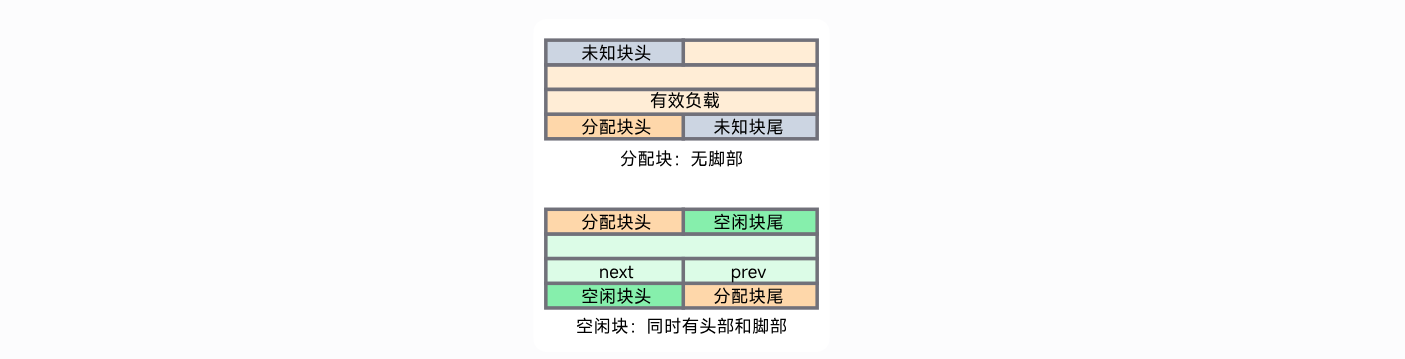
那么一个空闲块最少要四个字节header,footer以及next,prev来维护显式空闲链表。
注意:除了序言块和结尾块,一个指针调用时指向负载的第一个字节或者空闲块的prev字节。
块的头部一定是单字对齐,块的尾部一定是双字对齐。
针对逆天测试点的优化:
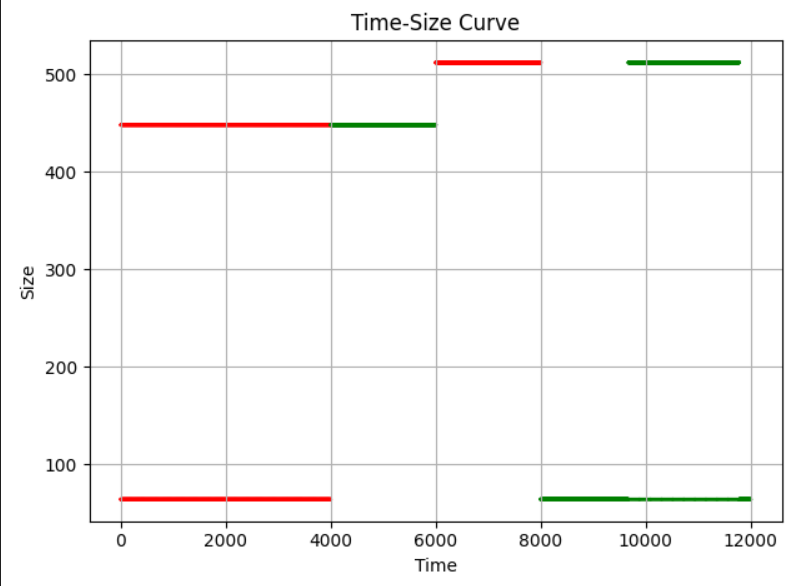
binary文件按照这样的分配逻辑来进行,我们应该怎么处理。
经过了长达20-30个小时的痛苦挣扎,我反思:
1.知道自己的每一行代码在干嘛,要很清晰。
2.两个size_t类型的数字相减一定是大于等于0的,我们在第一章就已经学习过了,但还是没有长记性。
3.哪怕是抄别人的代码也一定要搞清楚,并且不要抄错,否则,debug将是一种痛苦。
成品代码(96/100):
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <string.h>
#include <math.h>
#include "mm.h"
#include "memlib.h"
// 定义一些有用的宏,注意有些宏使用了其他的宏,那么你就要注意使用的顺序和方法
// 比较大小
#define MIN(X, Y) ((X) < (Y) ? (X) : (Y))
#define MAX(X, Y) ((X) > (Y) ? (X) : (Y))
// Header的大小
#define WORD_SIZE (sizeof(unsigned int))
#define CHUNK_SIZE (1 << 12)
// 用来在Header上写数据或者读取值
#define READ(PTR) (*(unsigned int *)(PTR))
#define WRITE(PTR, VALUE) ((*(unsigned int *)(PTR)) = (VALUE))
// 将块大小和是否被占用的信息合并,便于写入Header
#define PACK(SIZE, IS_ALLOC) ((SIZE) | (IS_ALLOC))
// 在alloc位的上一位记录这个块前面的块有没有被分配,这样类似,写入header
#define PACK_ALL(SIZE, IS_PREV_ALLOC, IS_ALLOC) ((SIZE) | (IS_PREV_ALLOC) | (IS_ALLOC))
// 传入指向Header的指针p,返回其后的负载块的长度
#define GET_SIZE(PTR) (unsigned int)((READ(PTR) >> 3) << 3)
// 传入指向Header的指针p,返回其后的负载块是否被占用
#define IS_ALLOC(PTR) (READ(PTR) & (unsigned int)1)
// 这是对于一个空闲块的操作,查看它前面的块有没有被分配
#define IS_PREV_ALLOC(PTR) (READ(PTR) & (unsigned int)2)
// 把这个块设置成已分配
#define SET_ALLOC(PTR) (READ(PTR) |= (unsigned int)1)
// 设置空闲
#define SET_FREE(PTR) (READ(PTR) &= ~0x1)
// 设置前面块已经分配
#define SET_PREV_ALLOC(PTR) (READ(PTR) |= (unsigned int)2)
// 设置前面块未分配
#define SET_PREV_FREE(PTR) (READ(PTR) &= ~0x2)
// 传入指向负载首个字节的指针,返回指向这个块的头/尾的指针
#define HEAD_PTR(PTR) ((char *)(PTR) - WORD_SIZE)
#define TAIL_PTR(PTR) ((char *)(PTR) + GET_SIZE(HEAD_PTR(PTR)) - WORD_SIZE * 2)
// 传入指向负载首个字节的指针,返回指相邻的下一个块/上一个块的指针
// 注意,指向的是负载块
#define NEXT_BLOCK(PTR) ((char *)(PTR) + GET_SIZE(HEAD_PTR(PTR)))
#define PREV_BLOCK(PTR) ((char *)(PTR) - GET_SIZE((char *)(PTR) - WORD_SIZE * 2))
// 用来debug的宏
#define IS_IN_HEAP(PTR) (((char *)(PTR) >= (char *)mem_heap_lo()) && ((char *)(PTR) <= (char *)mem_heap_hi()))
// 设置一个全局变量heap_list总是指向序言块
static char *heap_listp = 0;
// 空闲链表配置
#define FREE_LIST_NUMBER 14
// 一个头指针数组,每个指针指向该类链表的第一个空闲块
// 每个块存放的都是偏移量的大小
static char **free_lists;
#define FIND_TIMES 8
// 注意这里寻找的逻辑是相对于lo()的偏移量
#define PREV_OFFSET(bp) (*(unsigned *)(bp))
#define NEXT_OFFSET(bp) (*(unsigned *)((char *)(bp) + WORD_SIZE))
// 在这个位置我们只存放偏移量 prev next的
// 这两个一定要返回绝对的地址
#define PREV_NODE(bp) ((char *)(mem_heap_lo() + *(unsigned *)(bp)))
#define NEXT_NODE(bp) ((char *)(mem_heap_lo() + *(unsigned *)(bp + WORD_SIZE)))
//static int flag = 0;
// 我们在这里设置成偏移量
// #define SET_NODE_PREV(bp, val) (*(unsigned *)(bp) = ((unsigned)(val - mem_heap_lo())))
// #define SET_NODE_NEXT(bp, val) (*(unsigned *)((char *)bp + WORD_SIZE) = ((unsigned)(val - mem_heap_lo())))
#define SET_NODE_PREV(bp, val) (*(unsigned int *)(bp) = (unsigned int)((val) ? (char *)(val) - (char *)mem_heap_lo() : 0))
#define SET_NODE_NEXT(bp, val) (*(unsigned int *)((char *)(bp) + WORD_SIZE) = (unsigned int)((val) ? (char *)(val) - (char *)mem_heap_lo() : 0))
team_t team = {
/* Team name */
"Ciallo",
/* First member's full name */
"Quanye Yang",
/* First member's email address */
"2236115135@xjtu.edu.cn",
/* Second member's full name (leave blank if none) */
"",
/* Second member's email address (leave blank if none) */
""};
/* 用来做对齐的操作 */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
// 一些静态辅助inline函数的定义,减少开销
/* 合并空闲块 */
static inline void *coalesce(void *hp, size_t size);
/* 在一块找到的空间内分配内存 */
static inline void place(void *ptr, size_t size);
/* 首次适配的逻辑 */
static inline void *first_fit(size_t size);
/* 当对内存不够用时,堆内存扩展的逻辑 */
static inline void *extend_heap(size_t words);
static inline size_t get_index(size_t size);
static inline size_t adjust_size(size_t size);
static inline void insert_node(void *bp, size_t size);
static inline void delete_node(void *bp);
//static void debug_heap();
//static int test_number = 0;
// 合并空闲块
// check!!!
// void*是任意类型的指针
// 最容易出错的逻辑
static inline void *coalesce(void *hp, size_t size)
{
size_t is_prev_alloc = IS_PREV_ALLOC(HEAD_PTR(hp));
size_t is_next_alloc = IS_ALLOC(HEAD_PTR(NEXT_BLOCK(hp)));
if (is_next_alloc && is_prev_alloc)
{
// printf("两边都没有空闲块,大小为 %ld \n", size);
// 每次free都是前后已经分配并且是4096的大小?
// printf(" %ld ",size);
//++test_number;
// printf(" %d : %ld \n", test_number, size);
SET_PREV_FREE(HEAD_PTR(NEXT_BLOCK(hp)));
}
else if (is_prev_alloc && !is_next_alloc)
{
delete_node(NEXT_BLOCK(hp));
size += GET_SIZE(HEAD_PTR(NEXT_BLOCK(hp)));
//printf("后面有一个空闲块,合并之后大小为 %ld \n", size);
WRITE(HEAD_PTR(hp), PACK_ALL(size, 2, 0));
WRITE(TAIL_PTR(hp), PACK_ALL(size, 2, 0));
}
else if (!is_prev_alloc && is_next_alloc)
{
// 前面没有分配,稍微复杂一些
delete_node(PREV_BLOCK(hp));
SET_PREV_FREE(HEAD_PTR(NEXT_BLOCK(hp)));
size += GET_SIZE(HEAD_PTR(PREV_BLOCK(hp)));
//printf("前面有空闲块,合并之后大小为 %ld \n", size);
size_t is_prev_prev_alloc = IS_PREV_ALLOC(HEAD_PTR(PREV_BLOCK(hp)));
WRITE(HEAD_PTR(PREV_BLOCK(hp)), PACK_ALL(size, is_prev_prev_alloc, 0));
WRITE(TAIL_PTR(hp), PACK_ALL(size, is_prev_prev_alloc, 0));
hp = PREV_BLOCK(hp);
}
else
{
delete_node(PREV_BLOCK(hp));
delete_node(NEXT_BLOCK(hp));
size += (GET_SIZE(HEAD_PTR(PREV_BLOCK(hp)))) + (GET_SIZE(HEAD_PTR(NEXT_BLOCK(hp))));
//printf("两边都有空闲块,合并之后大小为 %ld \n", size);
size_t is_prev_prev_alloc = IS_PREV_ALLOC(HEAD_PTR(PREV_BLOCK(hp)));
WRITE(HEAD_PTR(PREV_BLOCK(hp)), PACK_ALL(size, is_prev_prev_alloc, 0));
WRITE(TAIL_PTR(NEXT_BLOCK(hp)), PACK_ALL(size, is_prev_prev_alloc, 0));
hp = PREV_BLOCK(hp);
}
insert_node(hp, size);
// debug_heap();
return hp;
}
// check!!! 如果有问题,大概就是空闲链表的设计有问题。
// place函数的全部,它传入指向一个空闲块的负载部分第一个字节的指针,以及需要从中分割出多少空间,你需要把分割出的一段或两段空间填写好相应的头部与尾部。
// 被binary攻击了,我们应当选取怎样的策略。
static inline void place(void *ptr, size_t size)
{
// assert(ptr != NULL);
size_t curr_size = GET_SIZE(HEAD_PTR(ptr));
size_t remaining_size = curr_size - size;
// printf("place(): ptr = %p, curr_size = %zu\n", ptr, curr_size);
// void *next = NEXT_BLOCK(ptr);
// printf("place(): next = %p\n", next);
// printf("place(): tail of next = %p, heap_hi = %p\n", TAIL_PTR(next), mem_heap_hi());
delete_node(ptr);
// 小于最小块的大小,那么我们就不会分割
if (remaining_size < 4 * WORD_SIZE)
{
SET_ALLOC(HEAD_PTR(ptr));
SET_PREV_ALLOC(HEAD_PTR(NEXT_BLOCK(ptr)));
// 如果下一个块是空闲块,那么尾部也要设置已经分配
if (!IS_ALLOC(HEAD_PTR(NEXT_BLOCK(ptr))))
{
SET_PREV_ALLOC(TAIL_PTR(NEXT_BLOCK(ptr)));
}
}
else
{
// 产生分割
WRITE(HEAD_PTR(ptr), PACK_ALL(size, IS_PREV_ALLOC(HEAD_PTR(ptr)), 1));
WRITE(HEAD_PTR(NEXT_BLOCK(ptr)), PACK_ALL(remaining_size, 2, 0));
WRITE(TAIL_PTR(NEXT_BLOCK(ptr)), PACK_ALL(remaining_size, 2, 0));
insert_node(NEXT_BLOCK(ptr), remaining_size);
// 我们来进行一些关于面向数据点的优化
// if (size <= 72)
// {
// //printf("分配成功了一下......");
// WRITE(HEAD_PTR(ptr), PACK_ALL(size, IS_PREV_ALLOC(HEAD_PTR(ptr)), 1));
// WRITE(HEAD_PTR(NEXT_BLOCK(ptr)), PACK_ALL(remaining_size, 2, 0));
// WRITE(TAIL_PTR(NEXT_BLOCK(ptr)), PACK_ALL(remaining_size, 2, 0));
// insert_node(NEXT_BLOCK(ptr), remaining_size);
// }
// else
// {
// // 把大的块放到后面去
// WRITE(HEAD_PTR(ptr), PACK_ALL(remaining_size, IS_PREV_ALLOC(HEAD_PTR(ptr)), 0));
// WRITE(TAIL_PTR(ptr), PACK_ALL(remaining_size, IS_PREV_ALLOC(HEAD_PTR(ptr)), 0));
// insert_node(ptr, remaining_size);
// ptr = NEXT_BLOCK(ptr);
// WRITE(HEAD_PTR(ptr), PACK_ALL(size, 0, 1));
// SET_PREV_ALLOC(HEAD_PTR(NEXT_BLOCK(ptr)));
// if(!IS_ALLOC(HEAD_PTR(NEXT_BLOCK(ptr)))){
// SET_PREV_ALLOC(TAIL_PTR(NEXT_BLOCK(ptr)));
// }
// }
}
// // 实验全部分配的代码
// size_t curr_size = GET_SIZE(HEAD_PTR(ptr));
// delete_node(ptr);
// WRITE(HEAD_PTR(ptr), PACK_ALL(curr_size, IS_PREV_ALLOC(ptr), 1));
// SET_PREV_ALLOC(HEAD_PTR(NEXT_BLOCK(ptr)));
// if(!IS_ALLOC(HEAD_PTR(NEXT_BLOCK(ptr)))){
// SET_PREV_ALLOC(TAIL_PTR(NEXT_BLOCK(ptr)));
// }
}
// check 逻辑应该没有问题,如果有问题,应该是显式链表的设计有问题
// 从开头开始遍历,直到找到第一个满足条件的分配块,并且返回指向负载部分第一个字节的指针
static inline void *first_fit(size_t size)
{
// 找一个合适的桶
int number = get_index(size);
char *hp;
// 从这个桶之后开始向后方进行遍历
for (; number < FREE_LIST_NUMBER; ++number)
{
// 怎么设计的显示分离空闲链表???
// 注意使用的是偏移量
// 但是在调用的时候,我们使用的都是真实的地址
for (hp = (char *)mem_heap_lo() + (size_t)free_lists[number]; hp != mem_heap_lo(); hp = NEXT_NODE(hp))
{
// 首次适配的逻辑
long diff = GET_SIZE(HEAD_PTR(hp)) - size;
if (diff >= 0)
{
//printf("The free block size is %d and the required size is %d...\n", GET_SIZE(HEAD_PTR(hp)), size);
long min_diff = diff;
char *cur = hp;
for (int index = 0; index < FIND_TIMES && cur != mem_heap_lo(); cur = NEXT_NODE(cur), ++index)
{
long s = GET_SIZE(HEAD_PTR(cur)) - size;
if (s >= 0 && s < min_diff)
{
min_diff = s;
hp = cur;
}
}
return hp;
}
}
}
return NULL;
}
// check!!!
// 用新的空闲块扩展堆
// 要扩展多少个字的大小
// 当我们指向尾部节点的时候,我们会扩展内存,这里的hp指向的是负载的内存(也就是才分配的),那么hp的前面就是刚才的结束foot,那么我们把刚才的结束foot设置成新的header,并且把才分配的内存的最后一个设置成结束foot,那么就处理了边界问题
static inline void *extend_heap(size_t words)
{
char *hp;
size_t size;
// 首先分配堆内存,必须要是偶数,因为要对齐8字节
size = (words % 2 == 1 ? ((words + 1) * WORD_SIZE) : (words * WORD_SIZE));
hp = mem_sbrk(size);
// printf("Here, we extended %d bytes\n", size);
if (hp == (void *)-1)
{
return NULL;
}
// 仔细思考一下,这是很精妙的处理边界情况的方式
// WRITE(HEAD_PTR(hp), PACK(size, 0));
// WRITE(TAIL_PTR(hp), PACK(size, 0));
// WRITE(HEAD_PTR(NEXT_BLOCK(hp)), PACK(0, 1));
size_t is_prev_alloc = IS_PREV_ALLOC(HEAD_PTR(hp));
WRITE(HEAD_PTR(hp), PACK_ALL(size, is_prev_alloc, 0));
WRITE(TAIL_PTR(hp), PACK_ALL(size, is_prev_alloc, 0));
WRITE(HEAD_PTR(NEXT_BLOCK(hp)), PACK(0, 1));
// 假如前面的一个块也是空闲的,调用合并空闲块的函数
return coalesce(hp, size);
}
// 根据不同的数值来获取不同大小的桶对应的链表位置
static inline size_t get_index(size_t size)
{
// if(size <= 4096)
// return 1;
// if (size <= 15360)
// return 11;
// if (size <= 30720)
// return 12;
// if (size <= 61440)
// return 13;
// else
// return 14;
// if (size <= 1)
// return 0;
// if (size <= 2)
// return 1;
// if (size <= 4)
// return 2;
// if (size <= 8)
// return 3;
// if (size <= 16)
// return 4;
// if (size <= 32)
// return 5;
// if (size <= 64)
// return 6;
// if (size <= 128)
// return 7;
// if (size <= 256)
// return 8;
// if (size <= 512)
// return 9;
// if (size <= 1024)
// return 10;
// if (size <= 2048)
// return 11;
// if (size <= 4096)
// return 12;
// if (size <= 8192)
// return 13;
// if (size <= 16384)
// return 14;
// if (size <= 32768)
// return 15;
// else
// return 16;
if (size <= 1)
return 0;
if (size <= 16)
return 1;
if (size <= 32)
return 2;
if (size <= 64)
return 3;
if (size <= 128)
return 4;
if (size <= 256)
return 5;
if (size <= 512)
return 6;
if (size <= 1024)
return 7;
if (size <= 2048)
return 8;
if (size <= 4096)
return 9;
if (size <= 8192)
return 10;
if (size <= 16384)
return 11;
if (size <= 32768)
return 12;
else
return 13;
// return 0;
}
static inline size_t adjust_size(size_t size)
{
if (size >= 112 && size < 128)
{
return 128;
}
// binary.rep
if (size >= 448 && size < 512)
{
// printf("Allocated size changed from %ld to %d...\n", size, 512);
return 512;
}
return size;
}
// 关于空闲链表的插入和删除
static inline void insert_node(void *bp, size_t size)
{
// 我们是往链表的头部进行插入
// 找到是属于第几个桶
size_t number = get_index(size);
// 该链表的头节点先拿出来
char *curr = (char *)mem_heap_lo() + (size_t)free_lists[number];
// free_lists存放了一系列的头节点
// 直接更新头节点为插入的节点
free_lists[number] = (char*)((char *)bp - (char *)mem_heap_lo());
// 插入的节点不是第一个节点
if (curr != mem_heap_lo())
{
// 把插入的bp作为链表的头节点
// 这里设置的是指向链表的地址
// 设置双向链表
SET_NODE_PREV(bp, mem_heap_lo());
SET_NODE_NEXT(bp, curr);
SET_NODE_PREV(curr, bp);
}
else
{
// bp是插入的第一个节点
SET_NODE_NEXT(bp, mem_heap_lo());
SET_NODE_PREV(bp, mem_heap_lo());
}
}
// check!!!
static inline void delete_node(void *bp)
{
assert(bp != NULL);
assert(!IS_ALLOC(HEAD_PTR(bp)));
size_t size = GET_SIZE(HEAD_PTR(bp));
size_t number = get_index(size);
char *next_node = NEXT_NODE(bp);
char *prev_node = PREV_NODE(bp);
// 是否是头节点
if (prev_node == mem_heap_lo())
{
// 是头节点就直接设置成下一个节点
free_lists[number] = (char*)((char *)next_node - (char *)mem_heap_lo());
// 是否是唯一的头节点
if (next_node != mem_heap_lo())
{
SET_NODE_PREV(next_node, mem_heap_lo());
}
}
else
{
// assert((int*)prev_node >= (int*)mem_heap_lo());
SET_NODE_NEXT(prev_node, next_node);
if (next_node != mem_heap_lo())
{
SET_NODE_PREV(next_node, prev_node);
}
}
}
/*
* mm_init - initialize the malloc package.
*/
// 这个实现要求返回的指针8字节对齐
// check!!!
// 设计上哪里还有漏洞,再比对一下
int mm_init(void)
{
// 先初始化空闲链表free_lists
// 开始时空闲链表的每个指针都定义成堆底的指针
free_lists = mem_heap_lo();
for (int index = 0; index < FREE_LIST_NUMBER; ++index)
{
// 每个分四字节
// 我们分配了FREE_LIST_NUMBER个双字,每个双字都用来存放链表的头指针
if ((heap_listp = mem_sbrk(2 * WORD_SIZE)) == (void *)-1)
{
return -1;
}
// 开始时free_lists所有的指向的地址都为堆底的地址
// 这里就是从堆底开始的15个双字,每个都存放着堆底的地址
free_lists[index] = 0;
}
// 此时双字对齐,我们开四个字来存放序言块和结尾块
if ((heap_listp = mem_sbrk(4 * WORD_SIZE)) == (void *)-1)
{
return -1;
}
// 紧接着我们来分配头部
// 第一个字填充
WRITE(heap_listp, 0);
// 后两个字是序言块,已分配的8字节
WRITE(heap_listp + (1 * WORD_SIZE), PACK(2 * WORD_SIZE, 1));
WRITE(heap_listp + (2 * WORD_SIZE), PACK(2 * WORD_SIZE, 1));
// 然后是结束标志的header,(Epilogue Header),大小为0,但是已经分配
// 这里的PACK3是自己分配,并且自己前方的块也已经分配的意思。
WRITE(heap_listp + (3 * WORD_SIZE), PACK(0, 3));
// heap_listp指向序言块的header,这样序言块就不会被释放
heap_listp += 2 * (WORD_SIZE);
// 申请一个page的内存失败。
if (extend_heap(CHUNK_SIZE / WORD_SIZE) == NULL)
{
return -1;
}
return 0;
}
/*
* mm_malloc - Allocate a block by incrementing the brk pointer.
* Always allocate a block whose size is a multiple of the alignment.
*/
// check!!! 唯一有可能是因为取整的问题出错
// 接下来要检查其余的函数
void *mm_malloc(size_t size)
{
// malloc的新逻辑
size_t alloc_size, extend_size;
void *hp;
if (heap_listp == NULL)
{
mm_init();
}
if (size == 0)
{
return NULL;
}
size = adjust_size(size);
// 保证对齐,可以用来存储头部或者脚部
if (size <= 2 * WORD_SIZE)
{
alloc_size = 4 * WORD_SIZE;
}
else
{
// 要分配的块向上取整
// 多了8个字节的大小
alloc_size = (2 * WORD_SIZE) * ((size + (WORD_SIZE) + (2 * WORD_SIZE - 1)) / (2 * WORD_SIZE));
// alloc_size = adjust_size(alloc_size);
// ++test_number;
// printf("%d:要分配%ld个字节......\n", test_number, alloc_size);
// printf("Alloc size is %ld...\n", alloc_size);
// size_t number = size / (2 * WORD_SIZE);
// number += 1;
// alloc_size = 2 * WORD_SIZE * number;
}
if ((hp = first_fit(alloc_size)) != NULL)
{
// ++test_number;
// printf("%d Alloc Size IS %d !!!\n", test_number, alloc_size);
place(hp, alloc_size);
return hp;
}
// 扩展堆,内存不足
// 也就是堆内存扩展的时候出了问题
extend_size = MAX(CHUNK_SIZE, alloc_size);
//++test_number;
// printf("%d:产生了堆扩展,扩展大小为 %ld 个字节\n", test_number, extend_size);
if ((hp = extend_heap(extend_size / WORD_SIZE)) == NULL)
{
return NULL;
}
place(hp, alloc_size);
return hp;
}
/*
* mm_free - Freeing a block does nothing.
* 释放本身是很简单的逻辑
*/
// check!!!
void mm_free(void *ptr)
{
if (ptr == NULL)
{
return;
}
if (heap_listp == NULL)
{
mm_init();
return;
}
size_t size = GET_SIZE(HEAD_PTR(ptr));
size_t is_prev_alloc = IS_PREV_ALLOC(HEAD_PTR(ptr));
// // 更改头部和尾部
// 因为这是一个空闲块,所以我们前后都要进行写入
WRITE(HEAD_PTR(ptr), PACK_ALL(size, is_prev_alloc, 0));
WRITE(TAIL_PTR(ptr), PACK_ALL(size, is_prev_alloc, 0));
// 合并空闲块的逻辑
coalesce(ptr, size);
}
/*
* mm_realloc - Implemented simply in terms of mm_malloc and mm_free
*/
void *mm_realloc(void *ptr, size_t size)
{
void *oldptr = ptr;
void *newptr;
size_t copySize;
newptr = mm_malloc(size);
if (newptr == NULL)
return NULL;
copySize = *(size_t *)((char *)oldptr - SIZE_T_SIZE);
if (size < copySize)
copySize = size;
memcpy(newptr, oldptr, copySize);
mm_free(oldptr);
return newptr;
}
// void debug_heap()
// {
// printf("======= 空闲链表状态 =======\n");
// for (int i = 0; i < FREE_LIST_NUMBER; ++i)
// {
// printf("FreeLists[%d]: ", i);
// char *bp = (char *)mem_heap_lo() + (size_t)free_lists[i];
// while (bp != mem_heap_lo())
// {
// printf("[%u] -> ", GET_SIZE(HEAD_PTR(bp)));
// bp = NEXT_NODE(bp);
// }
// printf("NULL\n");
// }
// }
一些注释还只是一些很少部分的debug记录,一定要反省!!!
我是真的垃圾。。。。。。