CSAPP:LinkerLab #
CSAPP上关于链接的知识我也会放在这里……
本文图片大多来源于英文原版CSAPP。
链接机制详解 #
有多详细?这很难定义吧,是否详细应当取决于读者本来的理解,linking本身就是看起来好像就是打包一下很简单的东西,但是涉及到的知识比较复杂,应用也相当广泛。
编译器驱动程序 #
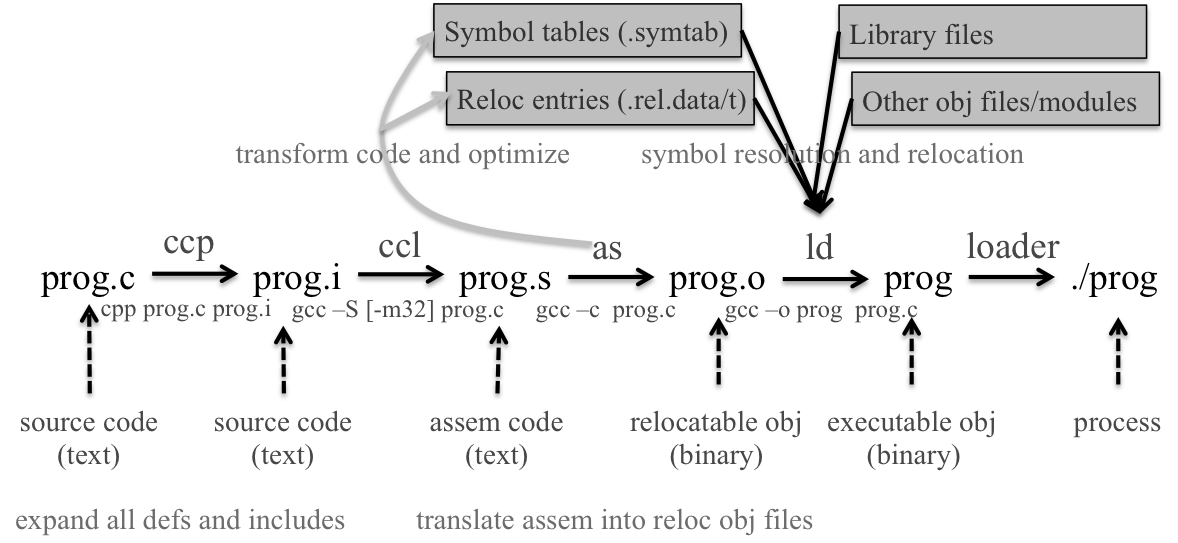
一个静态链接过程:
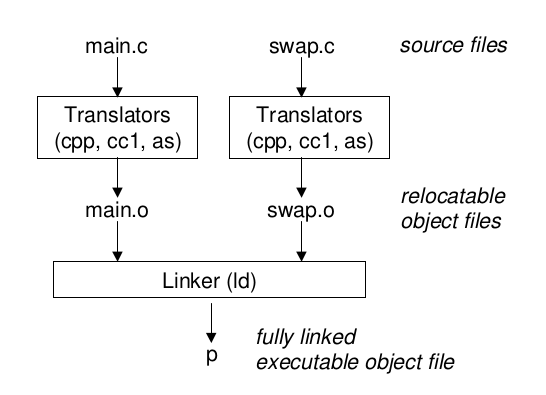
静态链接 #
LD 静态链接器 输入.o文件 输出一个可执行文件
1.符号的解析
2.重新定位
目标文件 #
1.可重定位
2.可执行
3.共享(可以动态加载进入内存并且link)
可重定位目标文件 #
意思就是这个文件作为一个目标文件,可以用来重定位。
很多人开始区分不清楚.o和elf:elf就是一种格式
包含的内容:

-
ELF 全称是 Executable and Linkable Format(可执行与可链接格式)
-
是 Linux 系统中常用的目标文件格式(Windows 上用的是 PE 格式)
-
一个 ELF 文件可以是:
- 可重定位目标文件(Relocatable Object File) →
.o文件 - 可执行文件(Executable File) → 如通过链接生成的可执行程序
- 共享库文件(Shared Object File) →
.so文件 - 核心转储文件(Core Dump) → 程序崩溃时生成的调试文件
- 可重定位目标文件(Relocatable Object File) →
-
.o文件是用编译器(如gcc -c)从.c文件生成的 -
.o文件的格式就是 ELF 格式的“可重定位目标文件” -
它通常还不包含主函数(
main()),不能直接运行,需要链接成可执行文件
一个典型的格式如下:
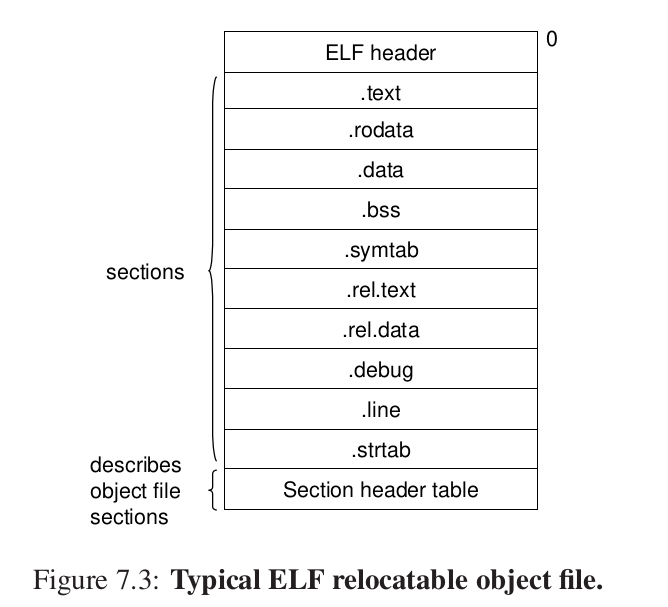
.text:机器代码
.rodata:只读data
.data:全局 静态变量
.bss:未初始化或者初始化为0的全局静态(better save space(?))
.symtab:符号表,函数和全局变量的信息
我们用readelf工具去读取头文件的内容,并且分析一下这个内容:
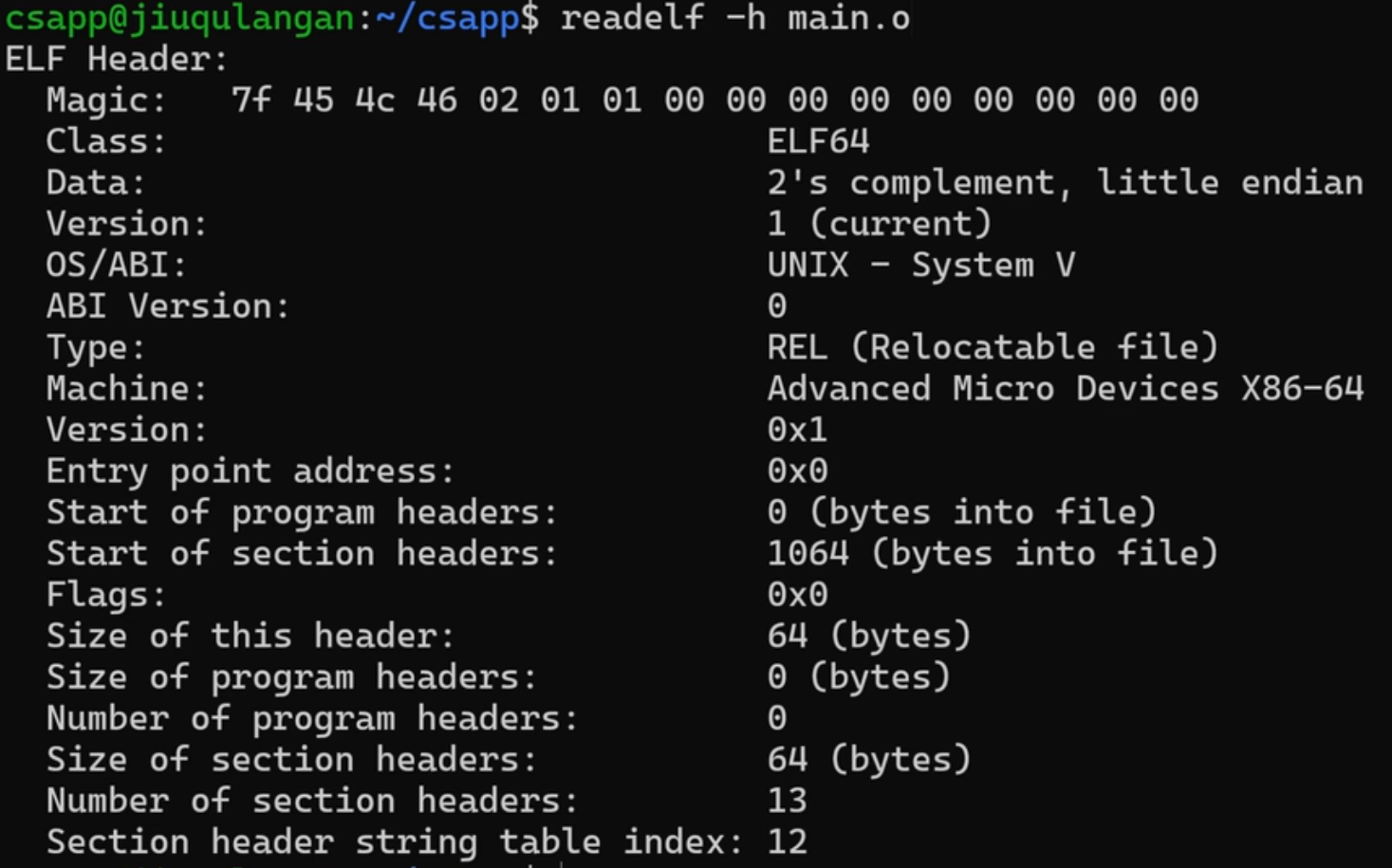
什么是Magic Number:标识了这个可重定位目标文件:
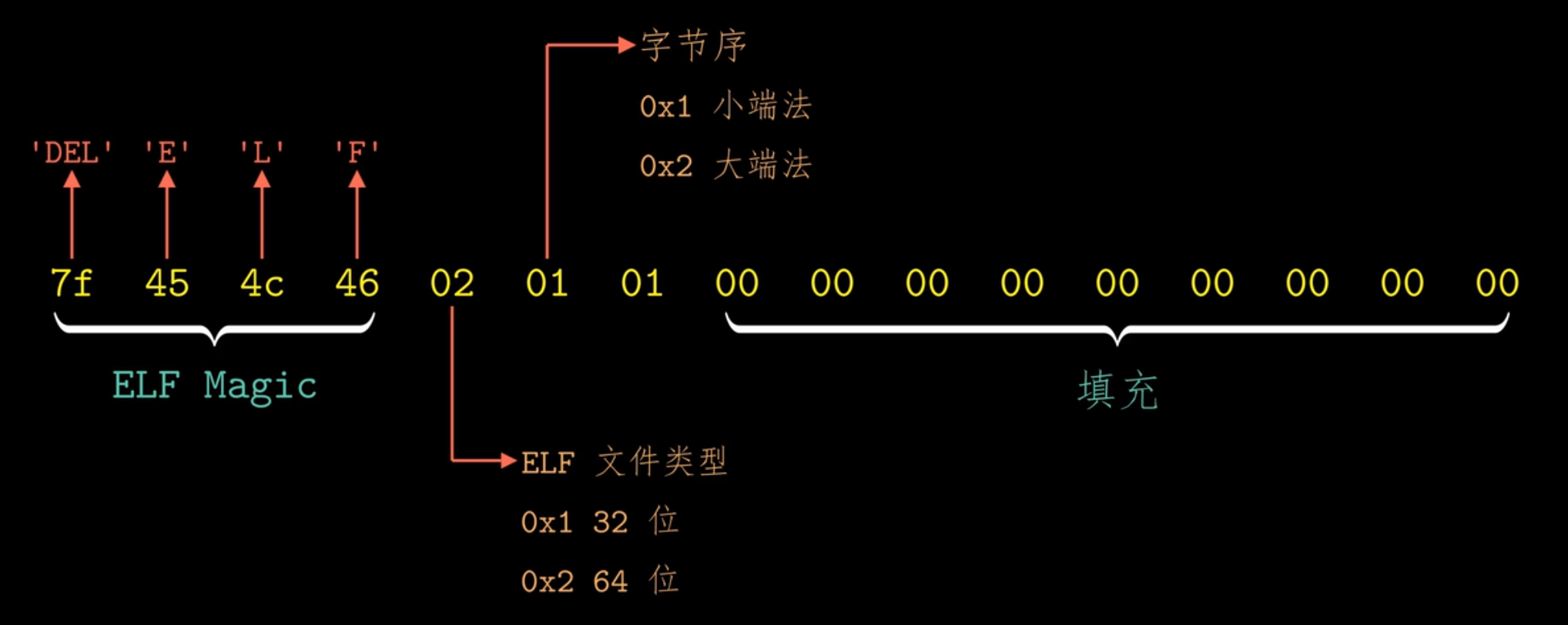
根据上述的信息,可以得到:
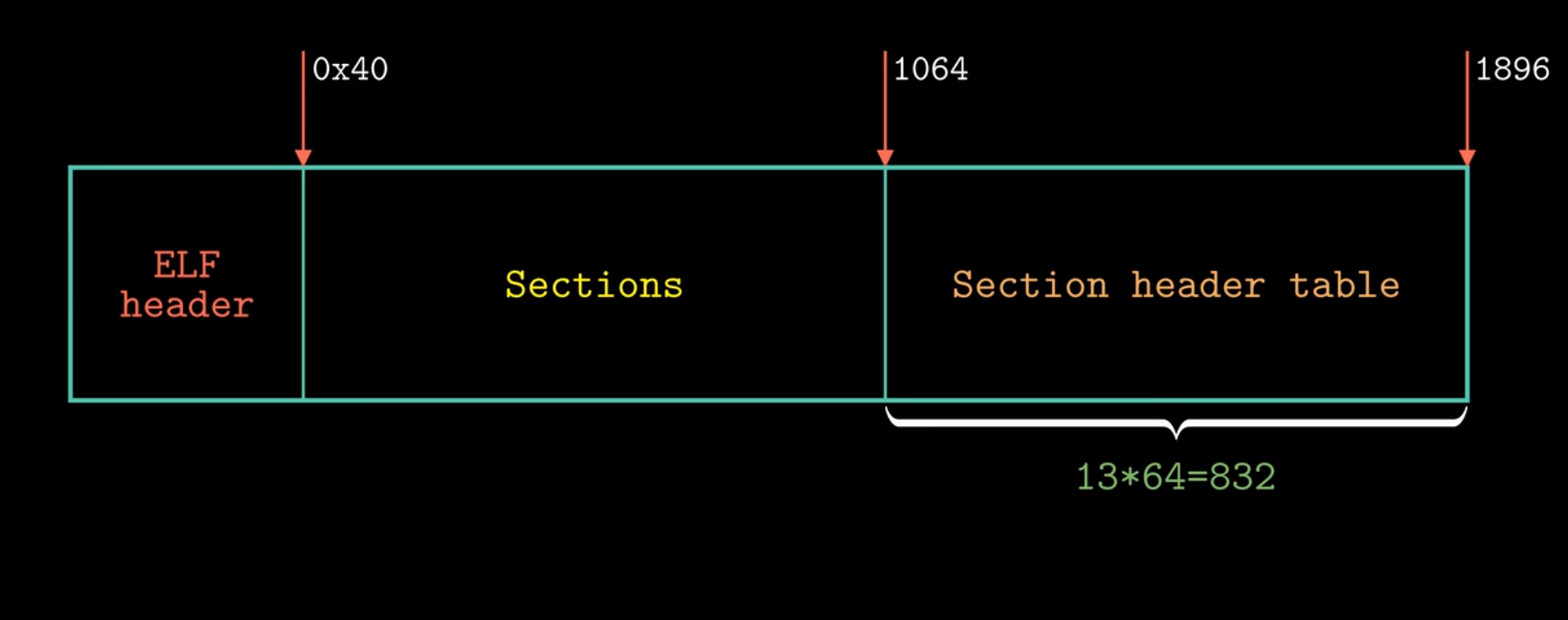
那么section中存放的:
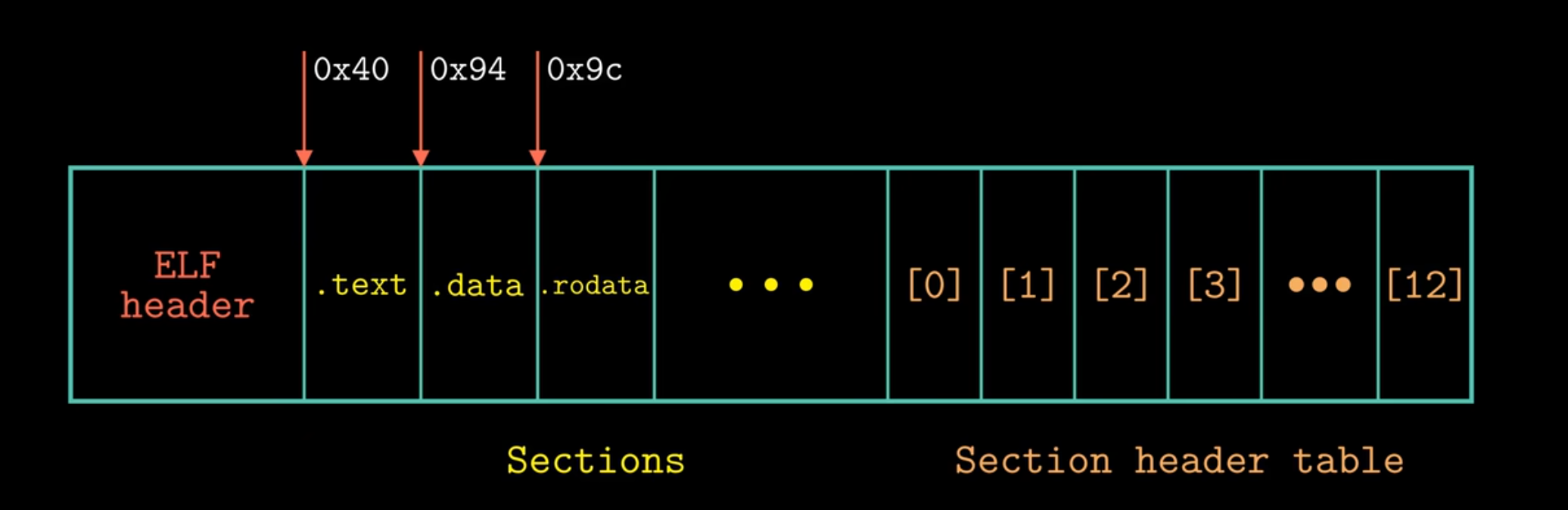
就如我们上面所提到的。
符号和符号表 #
*符号表是重点内容。
每个可重定位模块m都有一个符号表,这个symbol table就在section中。
1.全局符号 我定义的非静态C函数和全局变量。
2.外部符号 别人定义的非静态C函数和全局变量。
3.局部符号 我的static函数和局部变量(.symtab不关心这些东西),直接在stack中管理。
所以,在C语言多文件编程中,用static保护好自己的函数和变量是好的习惯。
不会被别人引用(明明是我先来的!!!)
符号表条目:

每个字段都被分配到目标文件的某个section
用 readelf 查看目标文件内容
| 选项 | 含义 |
|---|---|
-h |
查看 ELF 文件头(Header) |
|---|---|
-S |
查看段表(Section Headers) |
|---|---|
-s |
查看符号表(Symbol Table) |
|---|---|
-r |
查看重定位信息(Relocation Info) |
|---|---|
-l |
查看程序头表(Program Header) |
|---|---|
-x <section> |
以十六进制查看某个段的内容 |
|---|---|
-a |
查看所有信息(等价于所有选项的合集) |
|---|---|
main.c
int sum(int *a, int n);
int array[2] = {1, 2};
int main()
{
int val = sum(array, 2);
return val;
}
sum.c
int sum(int *a, int n)
{
int i, s = 0;
for (i = 0; i < n; i++)
{
s += a[i];
}
return s;
}
$readelf -s main.o
Symbol table '.symtab' contains 6 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS main.c
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1 .text
3: 0000000000000000 8 OBJECT GLOBAL DEFAULT 3 array
4: 0000000000000000 40 FUNC GLOBAL DEFAULT 1 main
5: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND sum
有点懵,务必做课后练习题进一步理解。
符号解析 #
链接器是怎样工作的?
对于每个输入的文件的符号表进行扫描。
多重定义的全局符号? #
全局—》强 弱
强符号:函数 已经初始化的全局变量
弱符号:未初始化的全局变量
规则:
1.强不能重名
2.一强多弱选强符号
3.多个弱符号随机选择(2,3都是比较危险的情况)
-fno-common:遇到多重定义的全局符号直接触发错误,比较保险。
是比较好理解的部分。
与静态库的链接? #
静态库作为存档(archieve)存放在磁盘中,可以认为是一组可重定位目标文件的集合,当我们自己的编程中引用库时就如下图所示:
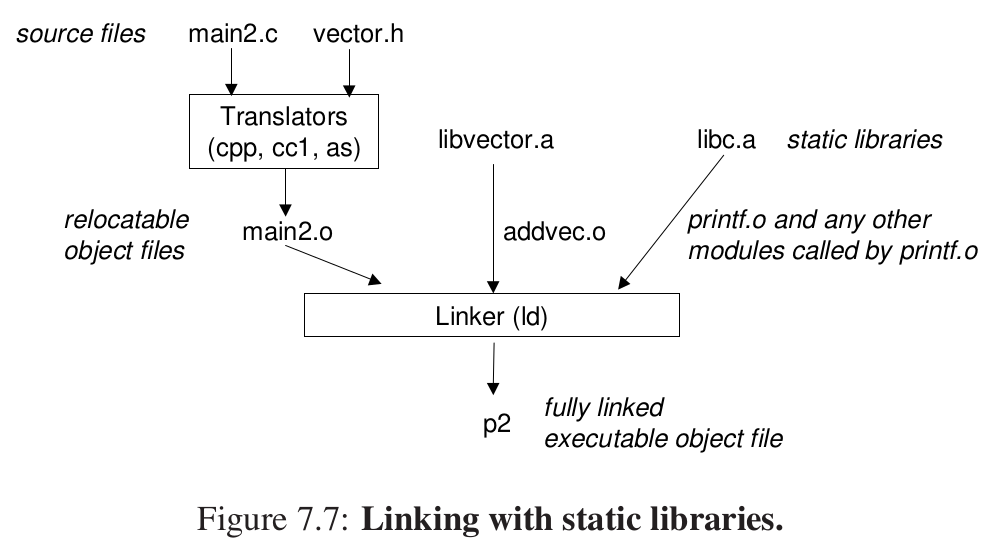
当你引用addvec时,直接复制addvec.o到可执行的文件。
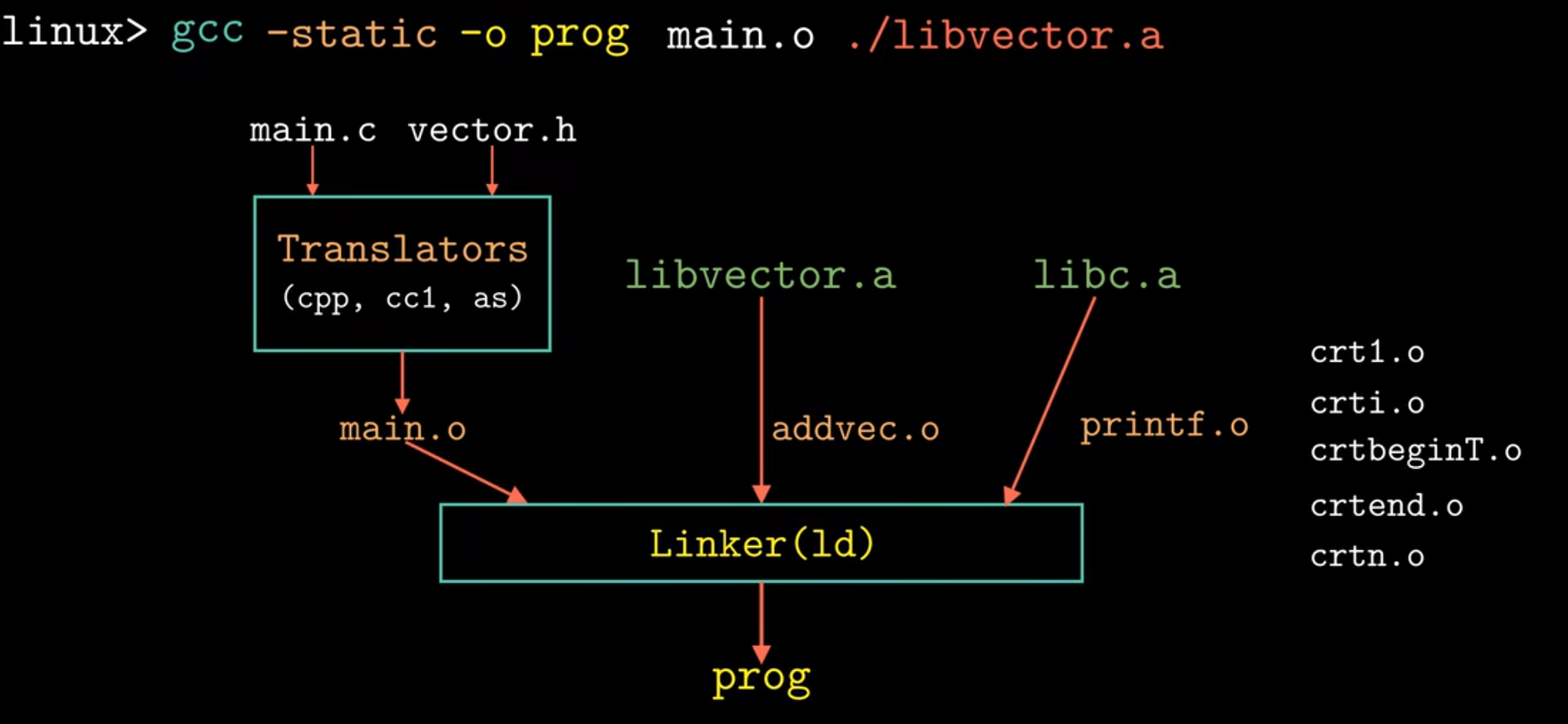
如何使用静态库解析引用? #
对于一行编译的命令,linker会从左到右进行扫描,维护三个集合:
1.E:维护可重定位目标文件的集合
2.U:未解析的符号的集合
3.D:前面输入文件的已经定义的符号的集合
process:
1.扫描过程中,若为一个目标文件f,直接放入E中,并且在U和D中更改元素(比如自己定义的符号就放到D,此时引用的静态库的符号就放到U)。
2.若f是一个archieve,那么我们将archive中的成员和U中的元素比对,如果定义了,就把这个元素放到D中去。
3.linker完成之后,|U| != 0 ,那么报错中止。
unix> gcc -static ./libvector.a main2.c
/tmp/cc9XH6Rp.o: In function ‘main’:
/tmp/cc9XH6Rp.o(.text+0x18): undefined reference to ‘addvec’
那么考察这样的情况,若你把静态库放到前面,那么开始就会和U中的元素比对,但是此时U中没有元素,当main.c被扫描时,此时它引用的静态库中的函数就会是undefined。
所以我们要把库放在最后,并且要根据库之间的依赖型进行排序(拓扑排序)。
如果有更复杂的依赖性问题,就可以多次在命令行上重复库(可以看课后题目)。
如下图所示的过程:

重定位 #
就是更换地址。
合并输入模块,为每个符号分配运行时地址。
1.重定位节和符号定义
比如把所有的**.data节合并成一个节并且分配地址**。
2.重定位节中的符号引用
修改符号引用,使其指向正确的运行时地址。
重定位条目 #
汇编器生成目标模块时生成.rel.data .rel.text 重定位条目

重定位符号引用 #
重定位算法遍历每个section和遍历每个条目:
foreach section s {
foreach relocation entry r {
refptr = s + r.offset; /* ptr to reference to be relocated */
/* relocate a PC-relative reference */
//相对地址
if (r.type == R_386_PC32) {
refaddr = ADDR(s) + r.offset; /* ref’s runtime address */
*refptr = (unsigned) (ADDR(r.symbol) + *refptr - refaddr);
}
//绝对地址
/* relocate an absolute reference */
if (r.type == R_386_32){
*refptr = (unsigned) (ADDR(r.symbol) + *refptr);
}
}
}
对于上面的main.o 做
objdump -dx main.o
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 83 ec 10 sub $0x10,%rsp
c: be 02 00 00 00 mov $0x2,%esi
11: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 18 <main+0x18>
14: R_X86_64_PC32 array-0x4
18: 48 89 c7 mov %rax,%rdi
1b: e8 00 00 00 00 call 20 <main+0x20>
1c: R_X86_64_PLT32 sum-0x4
20: 89 45 fc mov %eax,-0x4(%rbp)
23: 8b 45 fc mov -0x4(%rbp),%eax
26: c9 leave
27: c3 ret
这是我电脑上实际运行的结果,array和sum都是重定位PC相对引用
重定位PC相对引用 #
1b: e8 00 00 00 00 call 20 <main+0x20>
观察这一行,e8是call的操作码,后面的00 00 00 00 都是PC相对引用的占位符。
在重定位时,利用上述的算法,告诉我们sum在main中的偏移量,我们可以在这里调用到sum。
求两个地址之间的相对位置:
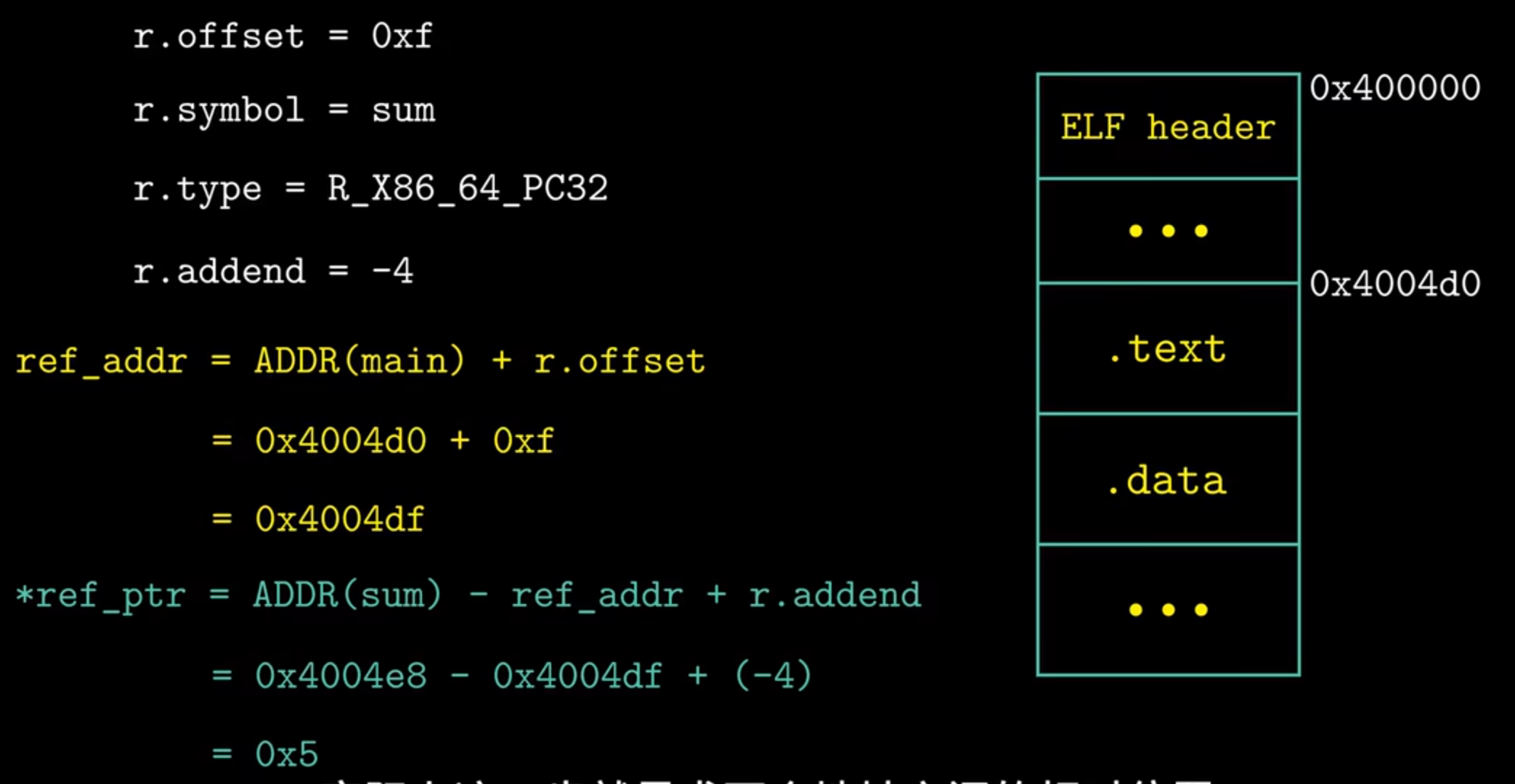
重定位绝对引用 #
在目标文件中直接计算并且更改。
在我们重定位之后:
0000000000001129 <main>:
1129: f3 0f 1e fa endbr64
112d: 48 83 ec 08 sub $0x8,%rsp
1131: be 02 00 00 00 mov $0x2,%esi
1136: 48 8d 3d d3 2e 00 00 lea 0x2ed3(%rip),%rdi # 4010 <array>
113d: e8 05 00 00 00 call 1147 <sum>
1142: 48 83 c4 08 add $0x8,%rsp
1146: c3 ret
0000000000001147 <sum>:
1147: f3 0f 1e fa endbr64
114b: ba 00 00 00 00 mov $0x0,%edx
1150: b8 00 00 00 00 mov $0x0,%eax
1155: eb 09 jmp 1160 <sum+0x19>
1157: 48 63 c8 movslq %eax,%rcx
115a: 03 14 8f add (%rdi,%rcx,4),%edx
115d: 83 c0 01 add $0x1,%eax
1160: 39 f0 cmp %esi,%eax
1162: 7c f3 jl 1157 <sum+0x10>
1164: 89 d0 mov %edx,%eax
1166: c3 ret
main中113e的位置就是sum的重定位地址。
这里的值5就是重定位的值:当CPU执行call指令时,PC会指向下一条就是1142,为了执行这个指令,CPU把PC放进栈中,并且 PC += 5,也就是PC = 1147,此时,就会执行到sum的代码。
这个逻辑是和call指令配套的,linker在🔗这两个程序的时候,就会根据重定位表,把e8之后的占位符更改成要调用的函数相对于当前PC的偏移量的大小,call会先将PC压入栈中,PC += offset,接着就会执行到目标函数。
可执行目标文件 #
我们现在已经合成了这个:
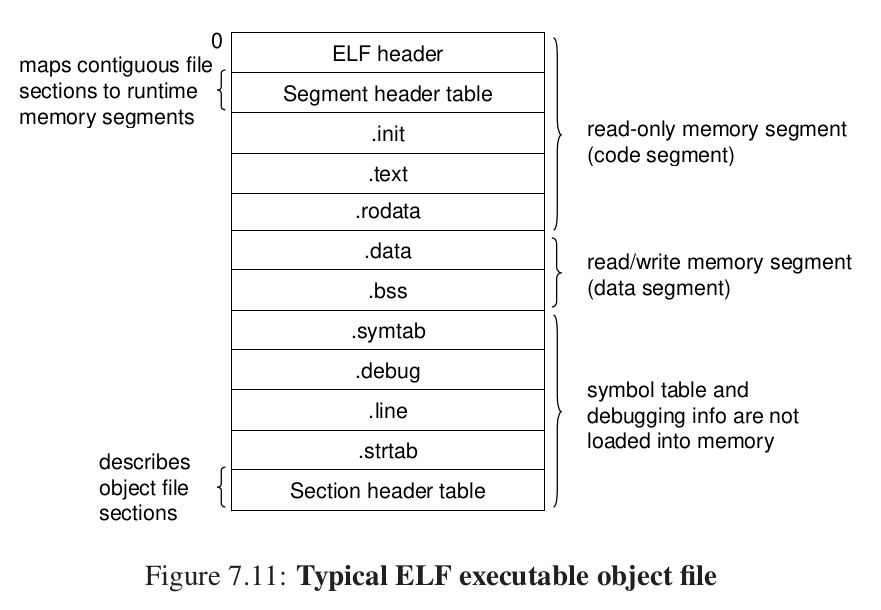
这是一个典型的格式。
我们查看一下上面那个a.out的program header
Program Header:
PHDR off 0x0000000000000040 vaddr 0x0000000000000040 paddr 0x0000000000000040 align 2**3
filesz 0x00000000000002d8 memsz 0x00000000000002d8 flags r--
INTERP off 0x0000000000000318 vaddr 0x0000000000000318 paddr 0x0000000000000318 align 2**0
filesz 0x000000000000001c memsz 0x000000000000001c flags r--
LOAD off 0x0000000000000000 vaddr 0x0000000000000000 paddr 0x0000000000000000 align 2**12
filesz 0x00000000000005f0 memsz 0x00000000000005f0 flags r--
LOAD off 0x0000000000001000 vaddr 0x0000000000001000 paddr 0x0000000000001000 align 2**12
filesz 0x0000000000000175 memsz 0x0000000000000175 flags r-x
LOAD off 0x0000000000002000 vaddr 0x0000000000002000 paddr 0x0000000000002000 align 2**12
filesz 0x00000000000000d8 memsz 0x00000000000000d8 flags r--
LOAD off 0x0000000000002df0 vaddr 0x0000000000003df0 paddr 0x0000000000003df0 align 2**12
filesz 0x0000000000000228 memsz 0x0000000000000230 flags rw-
DYNAMIC off 0x0000000000002e00 vaddr 0x0000000000003e00 paddr 0x0000000000003e00 align 2**3
filesz 0x00000000000001c0 memsz 0x00000000000001c0 flags rw-
NOTE off 0x0000000000000338 vaddr 0x0000000000000338 paddr 0x0000000000000338 align 2**3
filesz 0x0000000000000030 memsz 0x0000000000000030 flags r--
NOTE off 0x0000000000000368 vaddr 0x0000000000000368 paddr 0x0000000000000368 align 2**2
filesz 0x0000000000000044 memsz 0x0000000000000044 flags r--
0x6474e553 off 0x0000000000000338 vaddr 0x0000000000000338 paddr 0x0000000000000338 align 2**3
filesz 0x0000000000000030 memsz 0x0000000000000030 flags r--
EH_FRAME off 0x0000000000002004 vaddr 0x0000000000002004 paddr 0x0000000000002004 align 2**2
filesz 0x0000000000000034 memsz 0x0000000000000034 flags r--
STACK off 0x0000000000000000 vaddr 0x0000000000000000 paddr 0x0000000000000000 align 2**4
filesz 0x0000000000000000 memsz 0x0000000000000000 flags rw-
RELRO off 0x0000000000002df0 vaddr 0x0000000000003df0 paddr 0x0000000000003df0 align 2**0
filesz 0x0000000000000210 memsz 0x0000000000000210 flags r--
后面的是执行的权限的问题,vaddr是开始的内存地址,memsz是总共的内存大小,off偏移量,我们要满足这样的条件:
vaddr mod align = off mod align
这样程序执行的时候,可以有效率的传送到内存,我们会在虚拟内存的章节中学习到。
加载可执行目标文件 #
我们可能还会有一个关于加载器的实验,继续理解这个过程。
./prog
这样我们来运行一个自己写的程序,loader把代码和数据复制到内存中,并且跳转到内存的第一条指令或者入口点,这个复制的过程就叫 加载(Load)。
每个linux程序都有一个运行时内存映像。
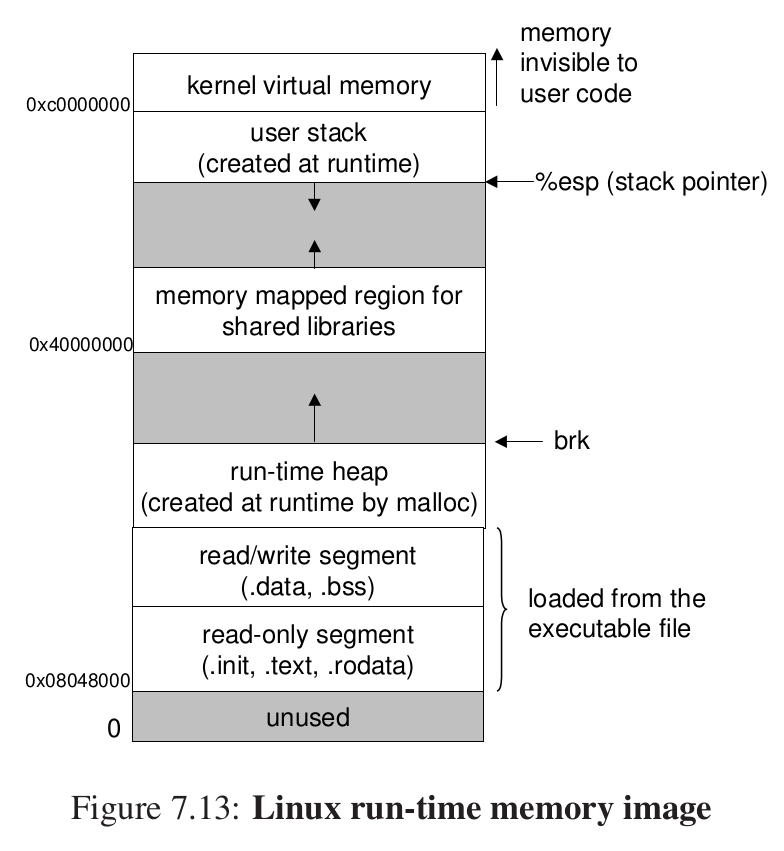
我们对于加载的描述从概念上来说是正确的,但也不是完全准确,这是有意为之。 要理解加载实际是如何工作的 ,你必须理解进程 、虚拟内存和内存映射的概念,这些我们还没有加以讨论 。在后面笫8章和笫9章中遇到这些概念时 ,我们将重新回到加载的问题上,并逐渐向你揭开它的神秘面纱。
实验: #
本实验就是模仿ld,写一个静态的linker,类似于linux的ld工具。
用简单的cpp就可以。
为什么要linker:为源代码的模块化提供可以相互引用的接口(extern)。
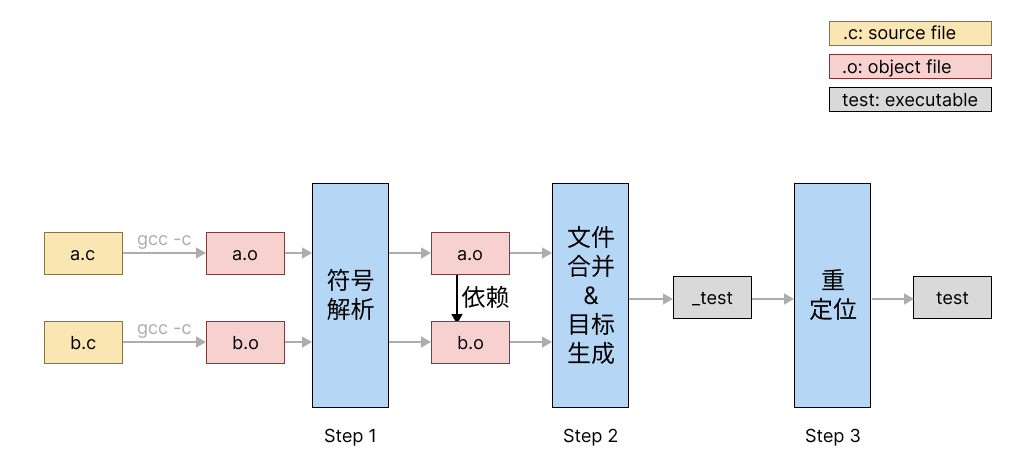
1.符号解析:为每个外部文件的符号引用找对应的解析。
2.合并成一个可执行文件。
3.重定位,修改可执行文件代码,使其指向正确的位置。
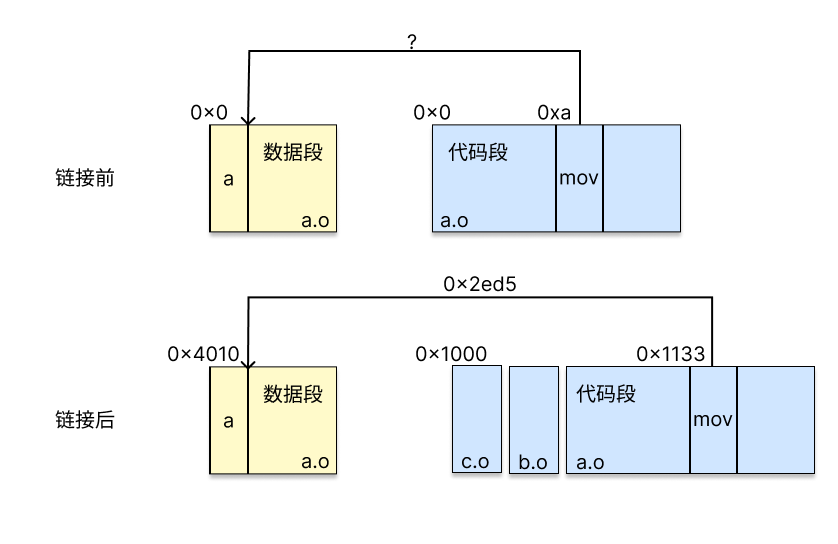
CPU使用PC相对引用访问地址。
重定位就是在合并之后,在这些空缺的位置填入地址。
实验框架:
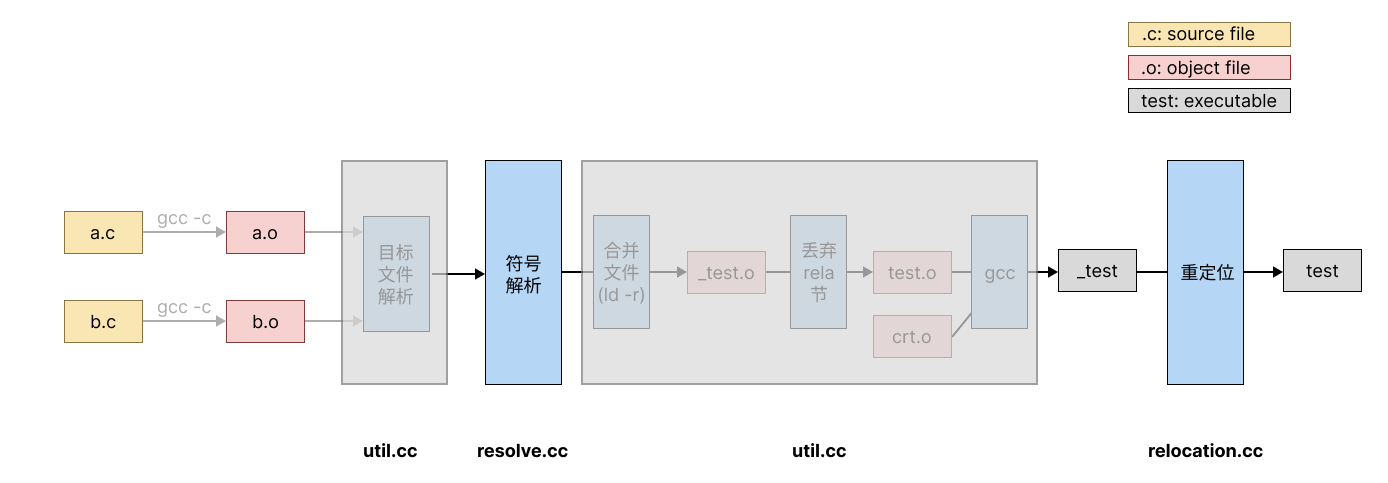
我们要实现的就是解析和重定位这两个关键过程。
理解关键的数据结构:
ObjectFile #
用来存储目标文件中所需的信息,其包含的成员变量及其含义如下:
- symbolTable :目标文件的符号表,保存其每一个符号(见下文Symbol)
- relocTable :目标文件的重定位表,保存其每一个重定位条目(见下文RelocEntry)
- sections :目标文件的节表,保存节名string到节的映射(见下文Section)
- sectionsByIdx :目标文件的节表,保存节索引index到节指针Section*的映射
- baseAddr :目标文件在内存中的起始地址,详见test0
- size :目标文件的大小
Section #
用来存储目标文件中的一个节,其包含的成员变量及含义如下:
- name :节名称
- type :节类型,在本实验中略
- flags :节标志,在本实验中略
- info :节附加信息,在本实验中略
- index :节下标
- addr :节的起始地址
- off :节在目标文件中的偏移量
- size :节大小
- align :节在目标文件中的对齐限制
关于type和flags的详细信息可参考[ELF文件的man手册中有关Shdr的部分](https://www.man7.org/linux/man-pages/man5/elf.5.html#:~:text=Section header (Shdr))。
Symbol #
用来存储目标文件中的一个符号,其包含的成员变量及含义如下:
- name :符号名称,为string类型。
- value :符号值,表示符号在其所属节中的偏移量。
- size :符号大小,当符号未定义时则为0
- type :符号类型,例如符号是变量还是函数
- bind :符号绑定,例如符号为全局或局部的
- visibility :符号可见性,本实验中略
- offset :符号在目标文件中的偏移量
- index :符号相关节的节头表索引
RelocEntry #
用来存储目标文件中的一个引用产生的重定位条目,其包含的成员变量及含义如下:
- sym :指向与该重定位条目关联的符号Symbol的指针
- name :重定位条目关联的符号名称,类型为string
- offset :重定位条目在节中的偏移量
- type :重定位条目类型
- addend :常量加数,用于计算要存储到可重定位字段中的值
allObject #
用来存储所有目标文件对应的ObjectFile数据结构。
mergedObject #
所有目标文件合并为一个后对应的ObjectFile。
对于 绝对重定位(如 R_X86_64_64):
结果=符号地址+addend\text{结果} = \text{符号地址} + \text{addend}结果=符号地址+addend
对于 PC 相对重定位(如 R_X86_64_PC32):
结果=符号地址+addend−当前地址\text{结果} = \text{符号地址} + \text{addend} - \text{当前地址}结果=符号地址+addend−当前地址
想一想:为什么R_X86_64_32对应的addend为0,而R_X86_64_PC32不是?addend有什么实际意义?
前面是绝对地址,我们是直接得到的,但是后面是PC相对寻址,也就是说call的时候,是相对于此时的PC的值的偏移量计算的,在找数组中的某个值的时候也非常有用。
重定位的逻辑: #
说到重定位就要考虑到重定位表的问题,我们要如何利用重定位表修改可执行目标文件中的占位符号(0000)。
#include "relocation.h"
#include <sys/mman.h>
// test0和test1都只需要进行重定位即可
// 重定位是加载这个程序之前我要修改值
void handleRela(std::vector<ObjectFile> &allObject, ObjectFile &mergedObject, bool isPIE)
{
/* When there is more than 1 objects,
* you need to adjust the offset of each RelocEntry
*/
// 合并之后,我们要更改偏移量,在大于1的情况下
if (allObject.size() > 1)
{
// 每次sum都要加上一整个节大小的偏移
uint64_t sum = 0;
for (auto &object : allObject)
{
for (auto &rel : object.relocTable)
{
rel.offset += sum;
}
sum += object.sections[".text"].size;
}
}
/* in PIE executables, user code starts at 0xe9 by .text section */
/* in non-PIE executables, user code starts at 0xe6 by .text section */
// 注意 textOff 和 textAddr 的区别:textOff 是指 .text 节在 ELF 文件中存储的位置,而 textAddr 是指 .text 节被运行时加载后在内存中所处的位置。
// 这里都是mergeObject的位置
uint64_t userCodeStart = isPIE ? 0xe9 : 0xe6;
uint64_t textOff = mergedObject.sections[".text"].off + userCodeStart;
uint64_t textAddr = mergedObject.sections[".text"].addr + userCodeStart;
for (auto &object : allObject)
{
for (auto &rel : object.relocTable)
{
// 直接转换
uint64_t baseAddr = reinterpret_cast<uint64_t>(mergedObject.baseAddr);
// 查看重定位的类型
// 相对寻址
if (rel.type == R_X86_64_PLT32 || rel.type == R_X86_64_PC32)
{
// 填入目标指令地址和当前PC的差值 + 补偿量
int val = rel.sym->value - (textAddr + rel.offset) + rel.addend;
// 注意这里的地址是32位的地址
*reinterpret_cast<int *>(baseAddr + textOff + rel.offset) = val;
}
// 这是绝对地址
else if (rel.type == R_X86_64_32)
{
int val = rel.sym->value + rel.addend;
*reinterpret_cast<int *>(baseAddr + textOff + rel.offset) = val;
}
else
{
fprintf(stderr, "There is something wrong...\n");
}
}
}
}
符号解析的逻辑: #
这和之前我们讨论库是怎么加载的是类似的,我们维护集合。
看了别人的代码,为了防止有抄袭的风险,我就有部分写的比较抽象。
#include "resolve.h"
#include <iostream>
#define FOUND_ALL_DEF 0
#define MULTI_DEF 1
#define NO_DEF 2
std::string errSymName;
int callResolveSymbols(std::vector<ObjectFile> &allObjects);
void resolveSymbols(std::vector<ObjectFile> &allObjects)
{
int ret = callResolveSymbols(allObjects);
if (ret == MULTI_DEF)
{
std::cerr << "multiple definition for symbol " << errSymName << std::endl;
abort();
}
else if (ret == NO_DEF)
{
std::cerr << "undefined reference for symbol " << errSymName << std::endl;
abort();
}
}
/* bind each undefined reference (reloc entry) to the exact valid symbol table entry
* Throw correct errors when a reference is not bound to definition,
* or there is more than one definition.
*/
// 这里我们要做三件事情1.找未定义的符号2.多重定义3.把弱符号绑定到强符号上面去
int callResolveSymbols(std::vector<ObjectFile> &allObjects)
{
// if found multiple definition, set the errSymName to problematic symbol name and return MULTIDEF;
// if no definition is found, set the errSymName to problematic symbol name and return NODEF;
// 维护两个集合,strong和weak
// 前面是name,后面是对应的*symbol
std::unordered_map<std::string, Symbol *> weakMap;
std::unordered_map<std::string, Symbol *> strongMap;
for (auto &object : allObjects)
{
// 遍历符号表
for (auto &symbol : object.symbolTable)
{
// 找到了一个强符号
if (symbol.index != SHN_UNDEF && symbol.index != SHN_COMMON && symbol.bind == STB_GLOBAL)
{
// 已经存在,表明多重定义
if (strongMap.find(symbol.name) != strongMap.end())
{
errSymName = symbol.name;
return MULTI_DEF;
}
else
{
// 原来没有,直接绑定
strongMap.emplace(symbol.name, &symbol);
}
}
}
}
// 把所有强符号绑定好了之后,再去处理弱符号
for (auto &object : allObjects)
{
for (auto &symbol : object.symbolTable)
{
if (symbol.index == SHN_COMMON && symbol.bind == STB_GLOBAL)
{
// 不存在直接绑定
if (weakMap.find(symbol.name) == weakMap.end())
{
weakMap.emplace(symbol.name, &symbol);
}
}
}
}
// 处理弱符号和强符号相同的情况
for (auto it = weakMap.begin(); it != weakMap.end(); ++it)
{
if (strongMap.find(it->first) != strongMap.end())
{
it->second->value = strongMap[it->first]->value;
it->second->index = strongMap[it->first]->index;
}
}
// 遍历重定位符号表,哪些符号要重定位但是没有在map里,说明未定义的错误
// 重定位的symbol在最后检查的时候被绑定
for (auto &object : allObjects)
{
for (auto &rel : object.relocTable)
{
if (strongMap.find(rel.name) != strongMap.end())
{
rel.sym = strongMap[rel.name];
}
else if (weakMap.find(rel.name) != weakMap.end())
{
rel.sym = weakMap[rel.name];
}
else
{
errSymName = rel.name;
return NO_DEF;
}
}
}
return FOUND_ALL_DEF;
}
总之,链接是一个复杂的话题,牵扯的知识很多且杂,还有动态DLL,库打桩机制等内容,之后再做了解。